2. 分布式架构演进
2.1 架构演进一: 早期雏形
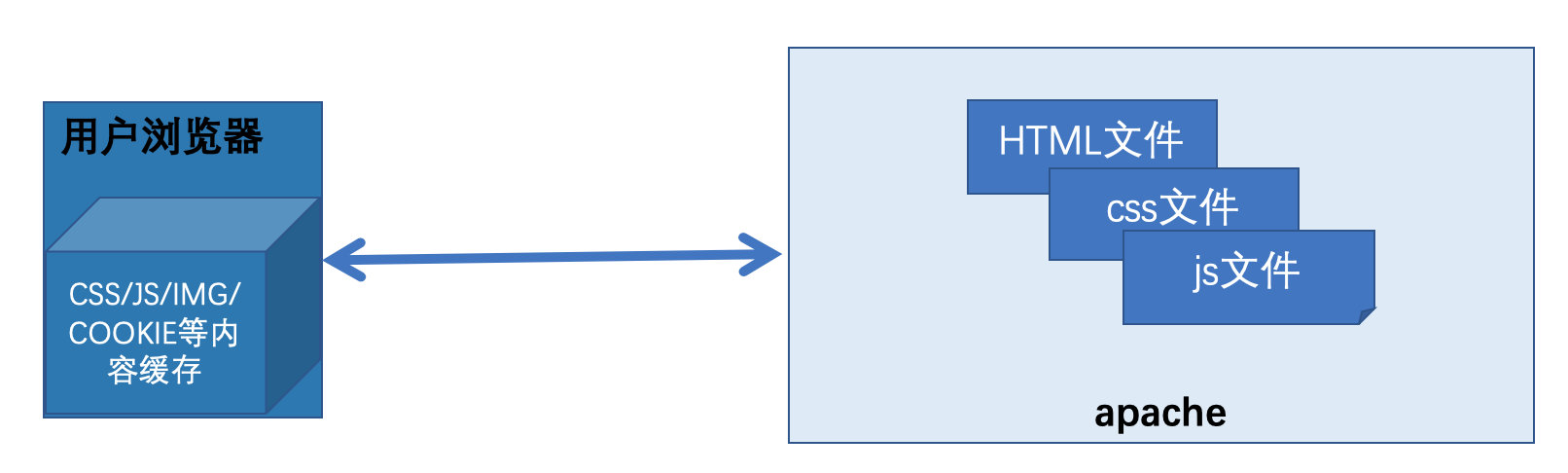
特征:应用程序主要做静态文件读取,返回内容给浏览器。
2.2 架构演进二: 数据库开发(LAMP特长)
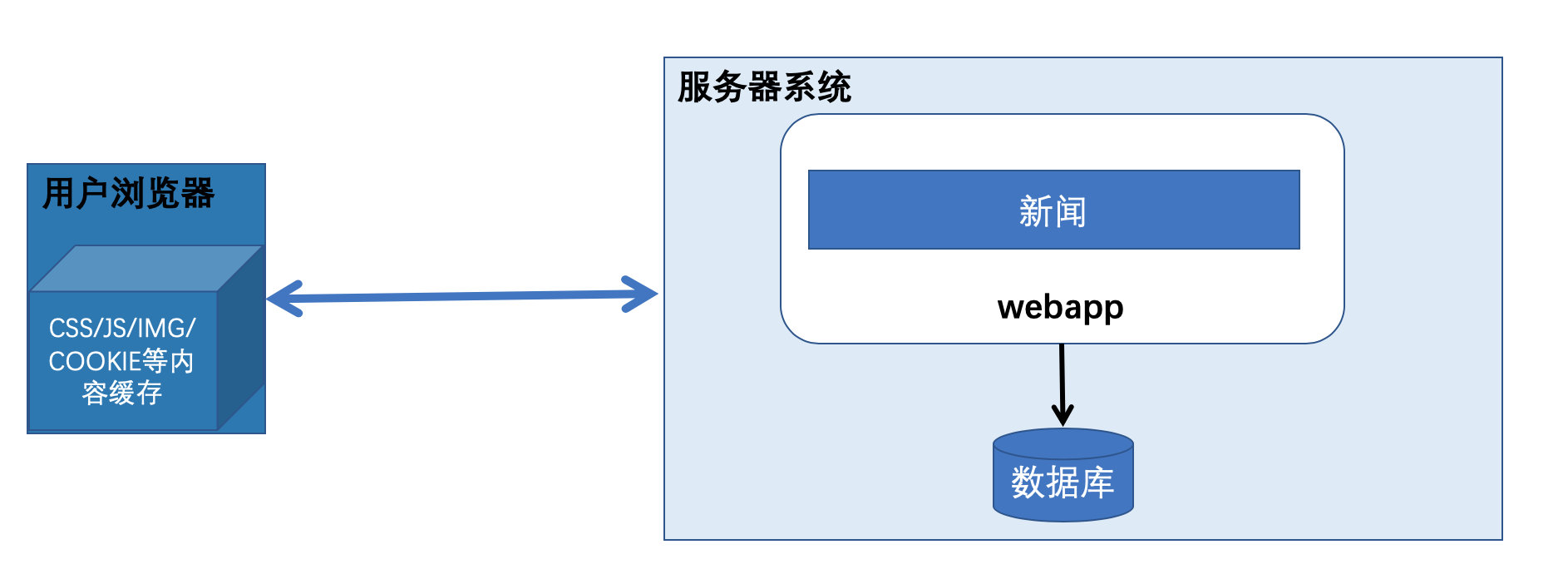
特征:应用程序主要主要读取数据表值,填充html模块。业务逻辑简单,写sql处理。
2.3 架构演进三: javaweb的雏形
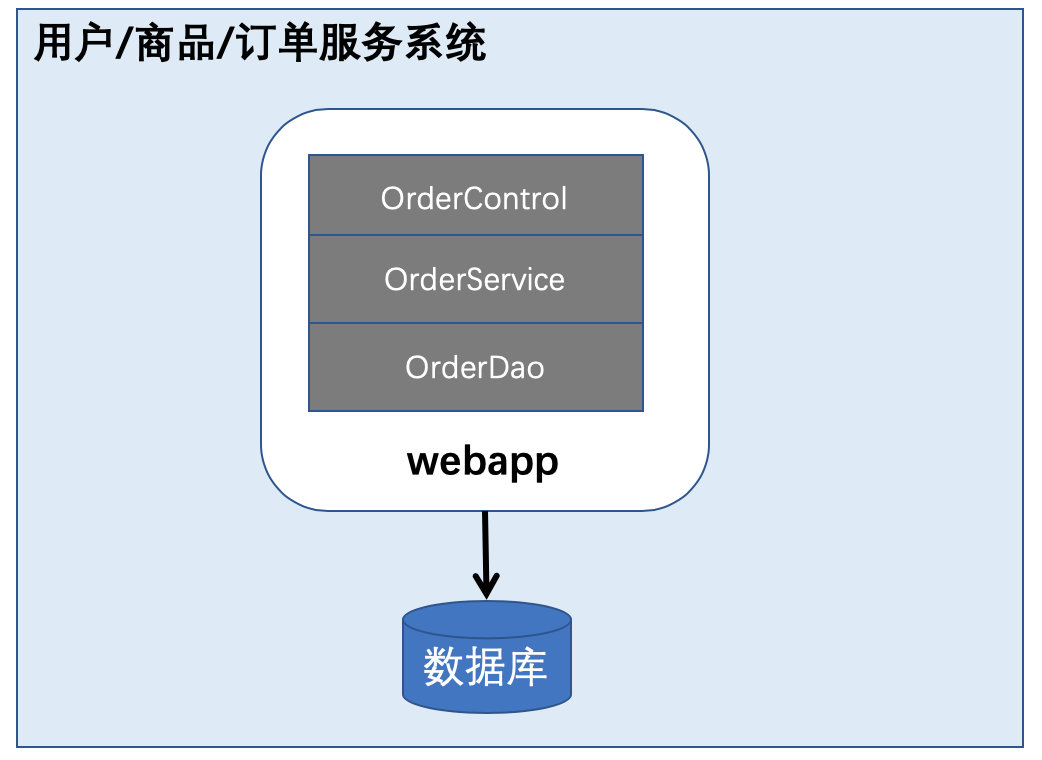
特征:tomcat + servlet + jsp + mysql。一个war包打天下
项目结构:ssh/ssm三层结构。
2.4 架构演进四: javaweb的集群发展
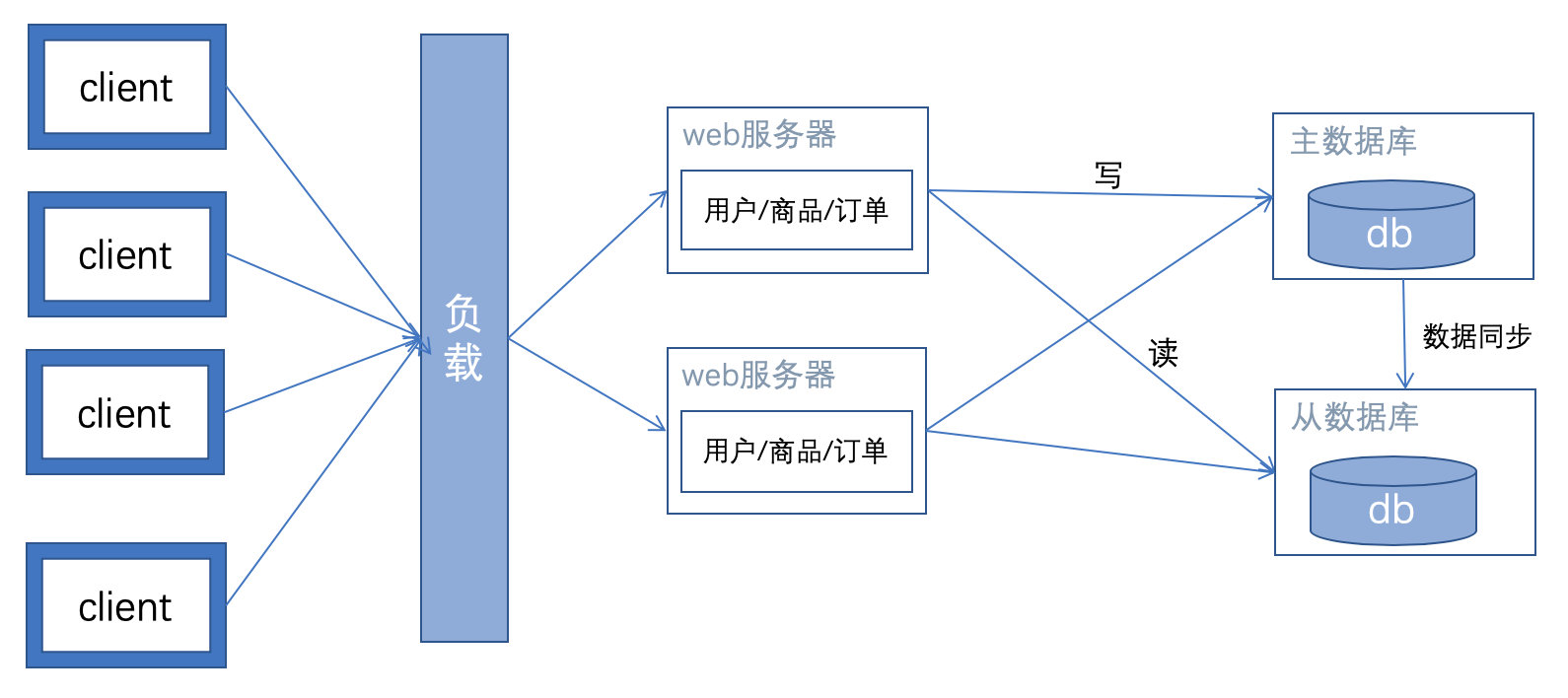
特征:硬件机器的横向复制,对整个项目结构无影响。
2.5 架构演进五: javaweb的分布式发展
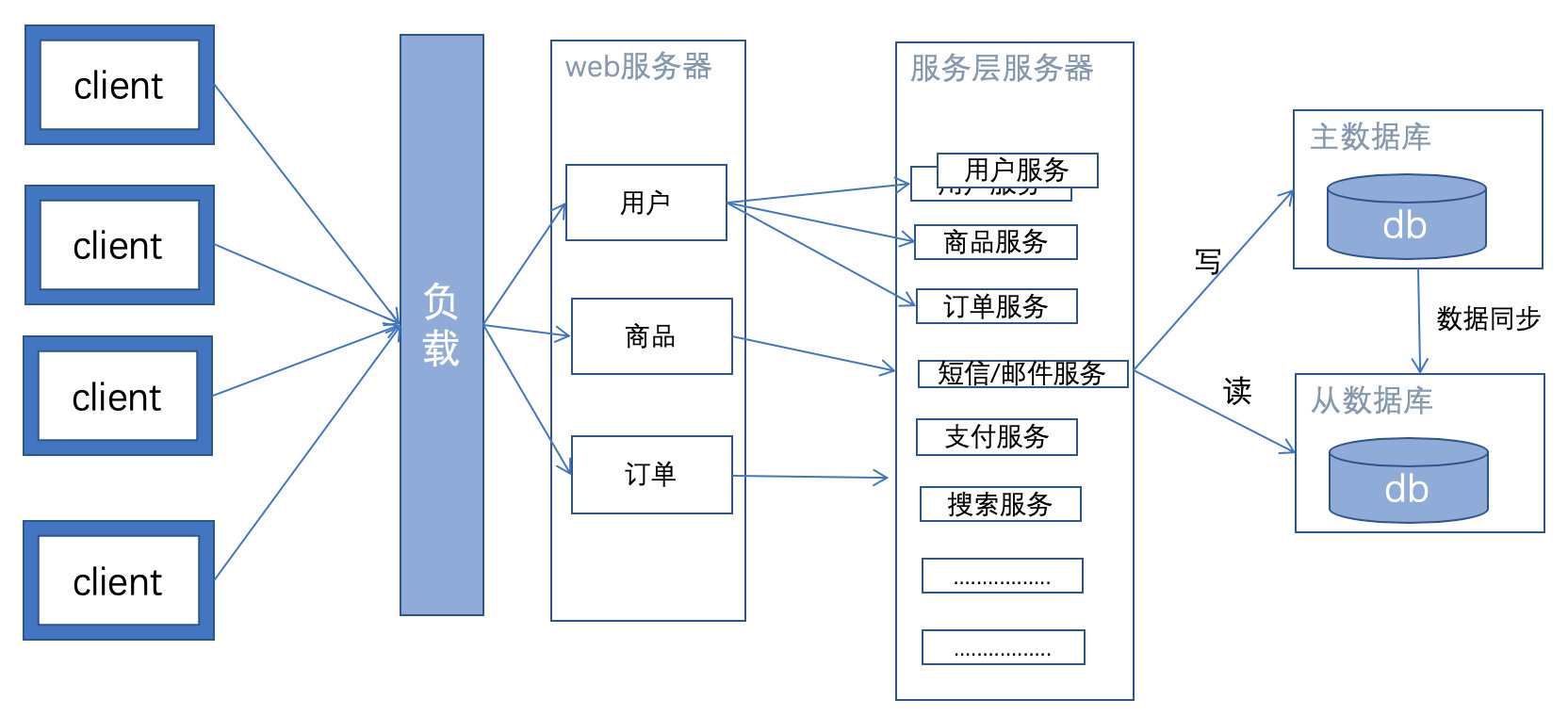
特征:将Service层单独分离出去,成为一个单独的项目jar。单独运行。
Web服务器通过rpc框架,对分离出去的service进行调用。
2.6 架构演进六: javaweb的微服务发展
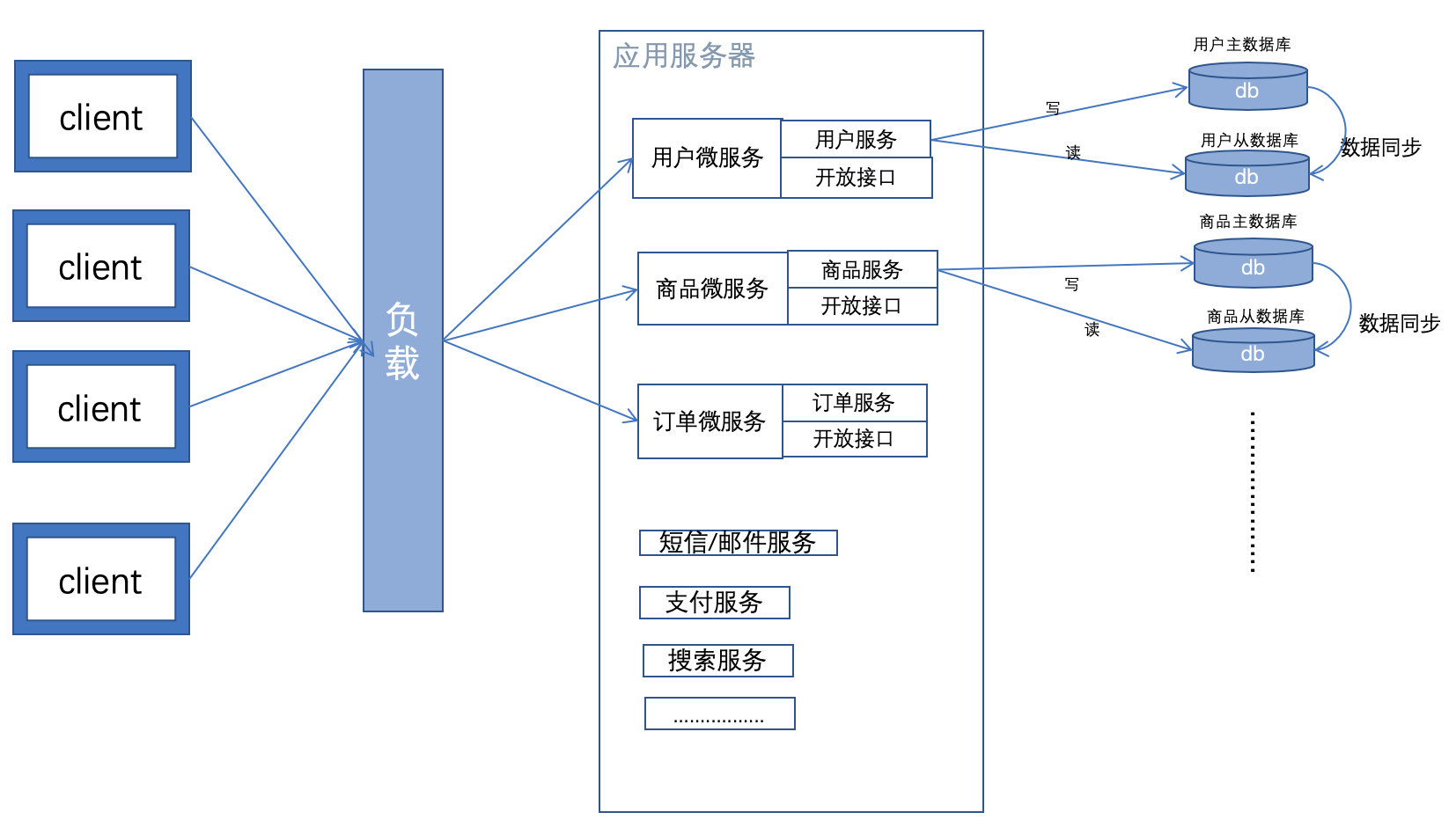
特征:从业务角度,细分业务为微服务,每一个微服务是一个完整的服务(从http请求到返回)。
在微服务内部,将需要对外提供的接口,包装成rpc接口,对外部开放。
2.6.1 SOA与微服务
微服务:把Control和service和dao全拆出来,独立为一个完整的服务,包括数据库。
SOA:将Service层单独分离出去,成为一个单独的项目jar,单独运行,其并不是一个完整的服务。
2.6.2 微服务优缺点
优点:
- 逻辑清晰
这个特点是由微服务的单一职责的要求所带来的。一个仅负责一项很明确业务的微服务,在逻辑上肯定比一个复杂的系统更容易让人理解。
逻辑清晰带来的是微服务的可维护性,在我们对一个微服务进行修改时,能够更容易分析到这个修改到底会产生什么影响,从而通过完备的测试保证修改质量。
- 简化部署
在一个单块系统中,只要修改了一行代码,就需要对整个系统进行重新的构建、测试,然后将整个系统进行部署。而微服务则可以对一个微服务进行部署。
这样带来的一个好处是,我们可以更频繁的去更改我们的软件,通过很低的集成成本,快速的发布新的功能。
- 可扩展
应对系统业务增长的方法通常采用横向(Scale out)或纵向(Scale up)的方向进行扩展。分布式系统中通常要采用Scale out的方式进行扩展。因为不同的功能会面对不同的负荷变化,因此采用微服务的系统相对单块系统具备更好的可扩展性。
- 灵活组合
在微服务架构中,可以通过组合已有的微服务以达到功能重用的目的。 比如在示例中,如果我们要新增一个Booking Service,在预订时可以直接重用Account Service和Inventory Service检查用户权限和库存情况。
- 技术异构
在一个大型系统中,不同的功能具有不同的特点,并且不同的团队可能具备不同的技术能力。因为微服务间松耦合,不同的微服务可以选择不同的技术栈进行开发。同时,在应用新技术时,可以仅针对一个微服务进行快速改造,而不会影响系统中的其它微服务,有利于系统的演进。比如在示例中,如果因为库存系统数据量变大,我们需要数据由当前的sqlite数据库修改为MySQL,可以仅修改Inventory Service,而不需要要求整个系统的数据库全部替换。
- 高可靠
微服务间独立部署,一个微服务的异常不会导致其它微服务同时异常。通过隔离、融断等技术可以避免极大的提升微服务的可靠性。
缺点:
- 复杂度高
微服务间通过REST、RPC等形式交互,相对于Monolithic模式下的API形式,需要考虑被调用方故障、过载、消息丢失等各种异常情况,代码逻辑更加复杂。
对于微服务间的事务性操作,因为不同的微服务采用了不同的数据库,将无法利用数据库本身的事务机制保证一致性,需要引入二阶段提交等技术。
同时,在微服务间存在少部分共用功能但又无法提取成微服务时,各个微服务对于这部分功能通常需要重复开发,或至少要做代码复制,以避免微服务间的耦合,增加了开发成本。
- 运维复杂
在采用微服务架构时,系统由多个独立运行的微服务构成,需要一个设计良好的监控系统对各个微服务的运行状态进行监控。运维人员需要对系统有细致的了解才对够更好的运维系统。
- 影响性能
相对于Monolithic架构,微服务的间通过REST、RPC等形式进行交互,通信的时延会受到较大的影响。
2.7 架构改进中常见解决方案
架构改进的依据,主要是并发数和数量级,通常来讲有如下几种手段:
1、缓存(list/redis/memached)
2、横向拓展(集群负载)
3、拆分高负载服务,独立为一模块
4、大表数据切片( mysql分库分区分表)
5、使用搜索中间件: solr/elasticsearch
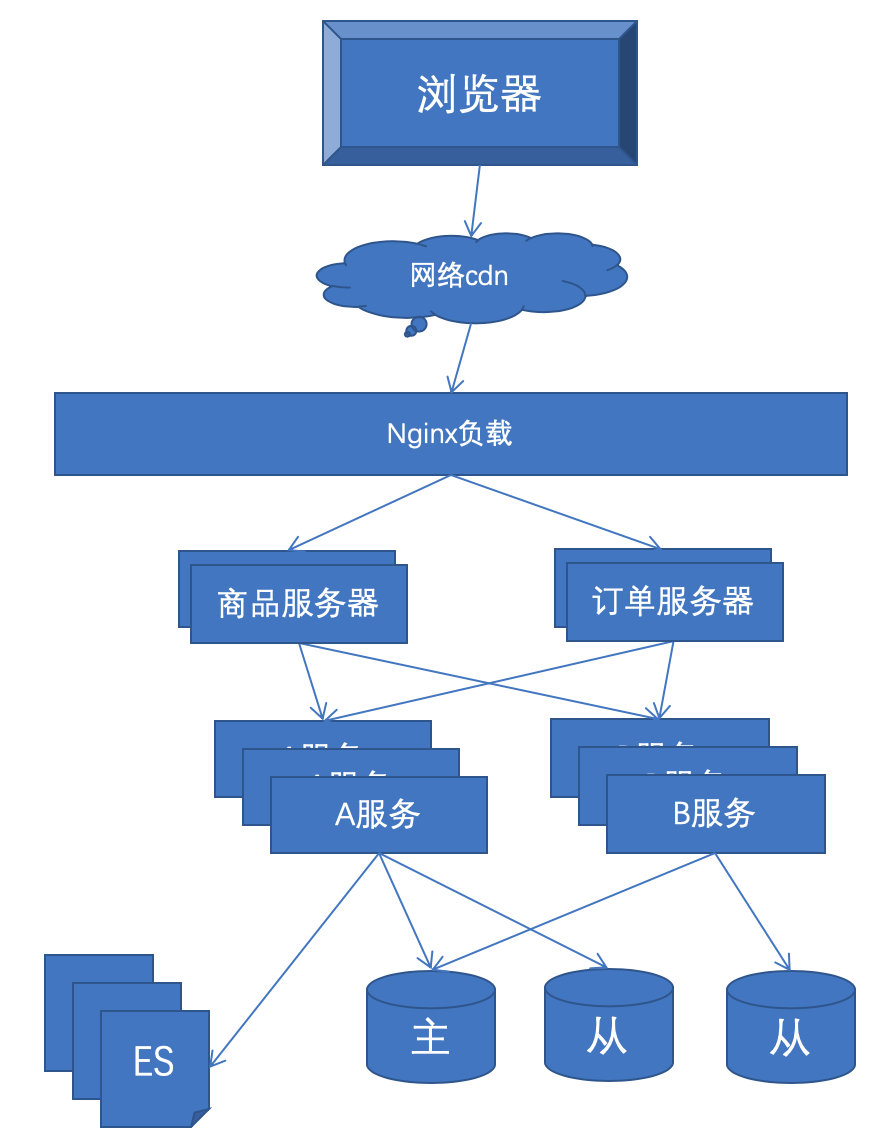
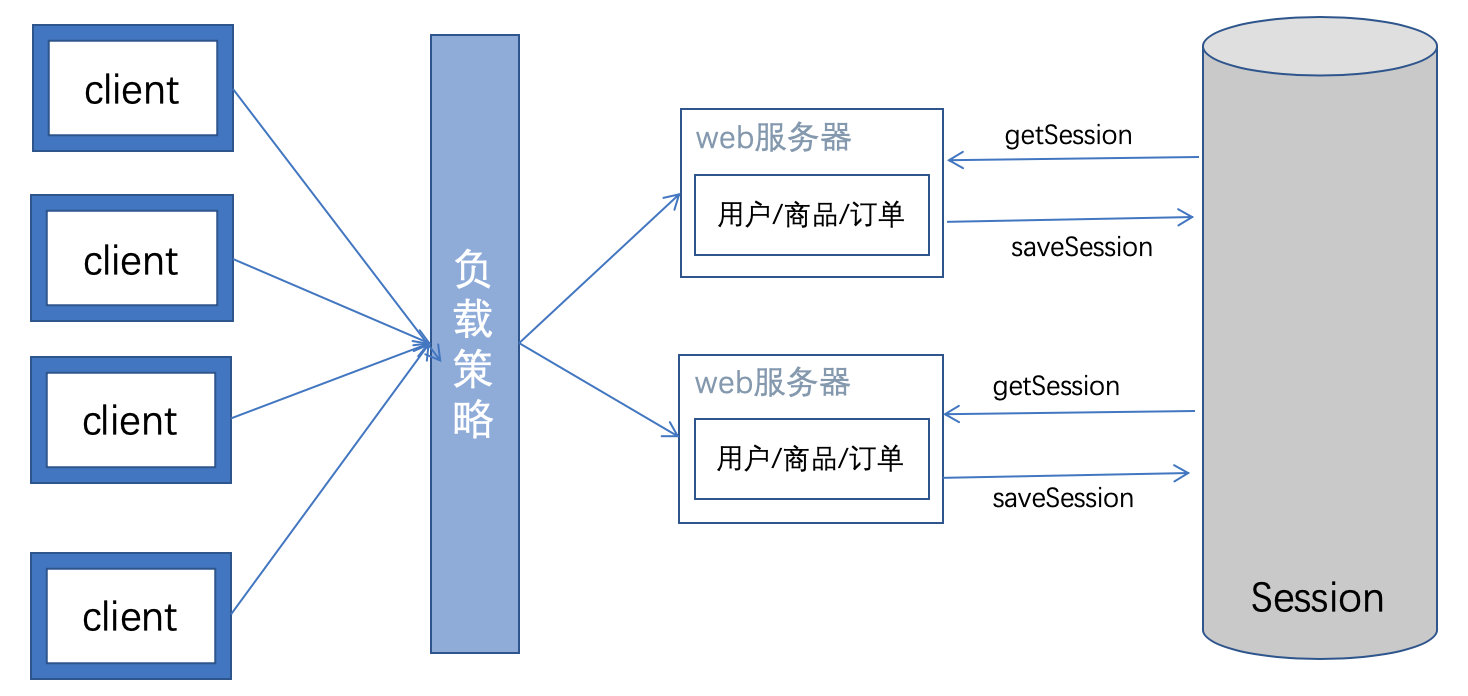
2.7.1 架构解决: session跨域共享
方案1:负载使用 hash(ip),根据ip将用户导入相同的服务器,避免session失效的问题。
方案2:使用redis共享session,专门用redis来存放所有的session。
2.7.2 架构解决: 缓存方案
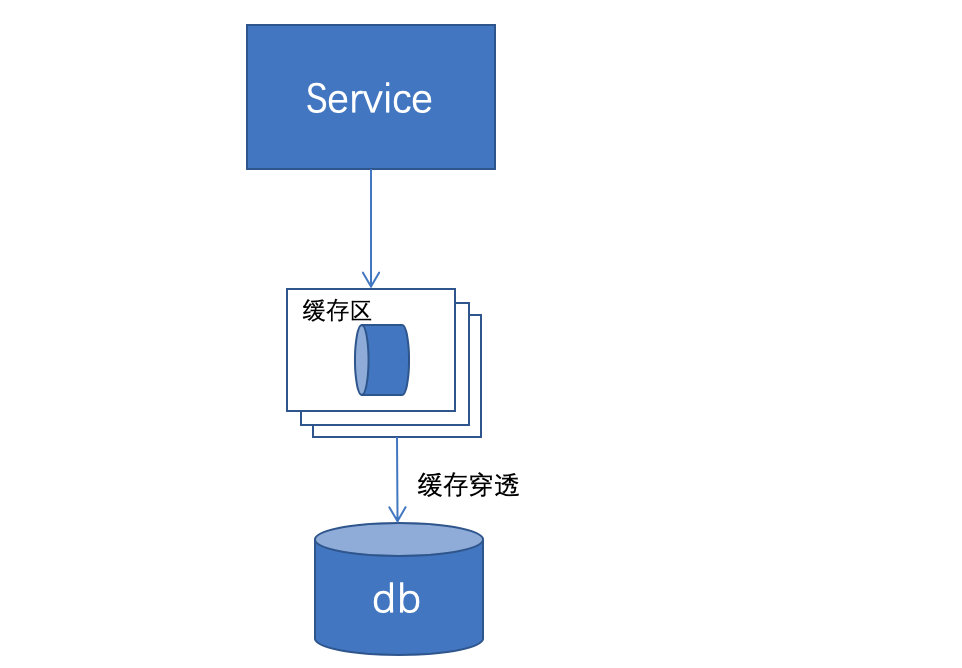
一般缓存方案
1、先到缓存中查,有值直接返回
2、无值(缓存穿透、击穿)则调用接口或者查库,并将值补入缓存区
3、缓存区数据与db中可能不一致,使用过期时间调节
4、若缓存区数据集中在某一短时刻失效,将导致大量的缓存击穿(雪崩)
永不过期方案
1、不设置过期时间,数据永久有效,避免雪崩
2、需要额外机制来实现数据的同步更新(参照数据同步
2.7.3 架构解决: mq方案
消息中间件可以用于服务解耦。
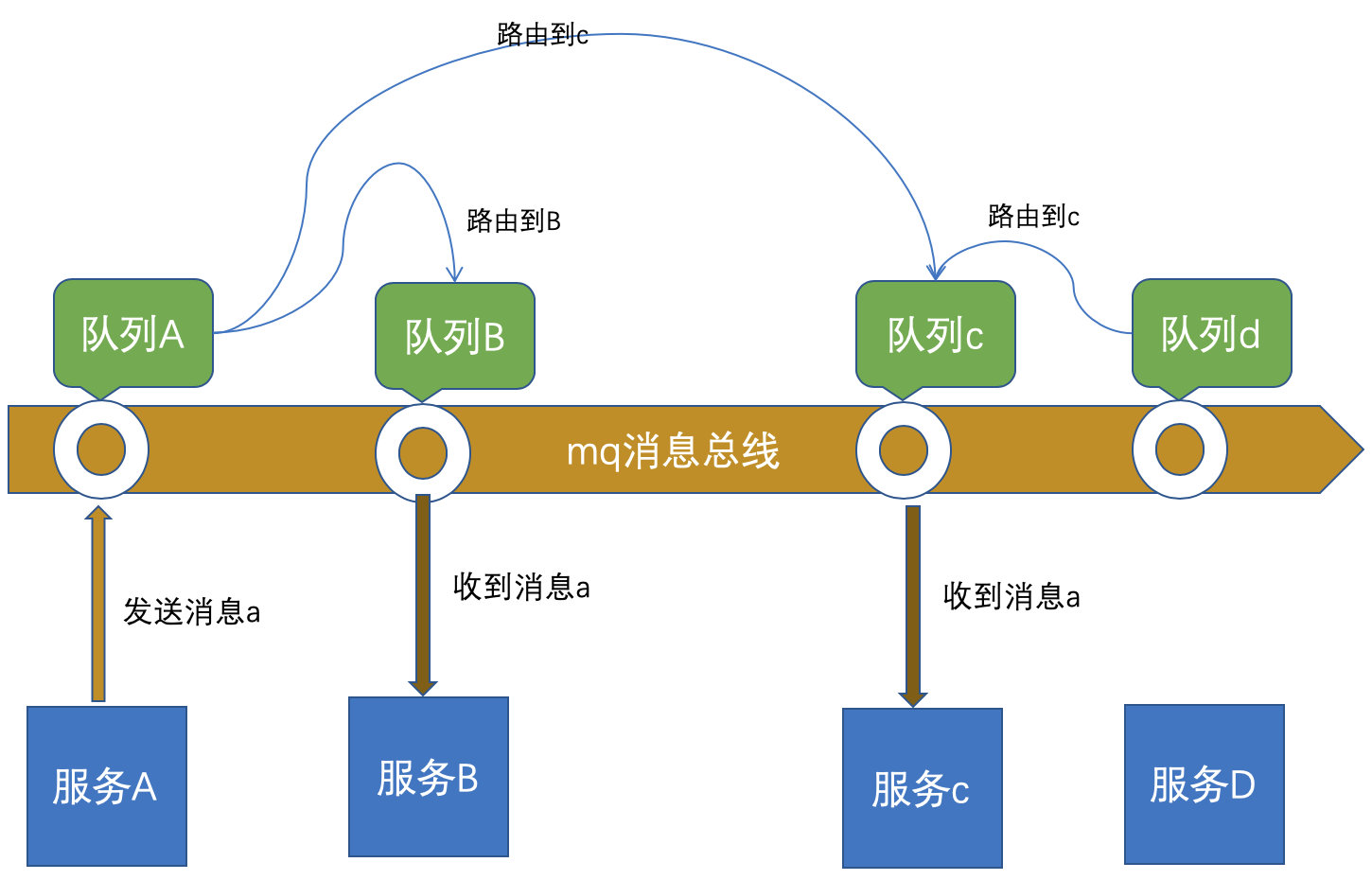
1、每个应用启动时,主动注册队列
2、后续收/发信息,只管收/发队列中数据
3、队列中数据的路由策略,由mq管理者来配置,跟应用程序无关
2.7.4 同步、异步
同步调度:
1、调度期间,主调和被调线程被同时占用。
2、被调执行完成前,主调等待。
3、程序内部的调度,则为一单线程。
异步调度:
1、主调与被调只是一次消息发送,信息到达即返回。
2、被调执行完成后,回调一次主调方,发送结果回来。
3、程序内部的调度,则回调函数是由被调线程执行。

2.7.5 架构解决:数据分片
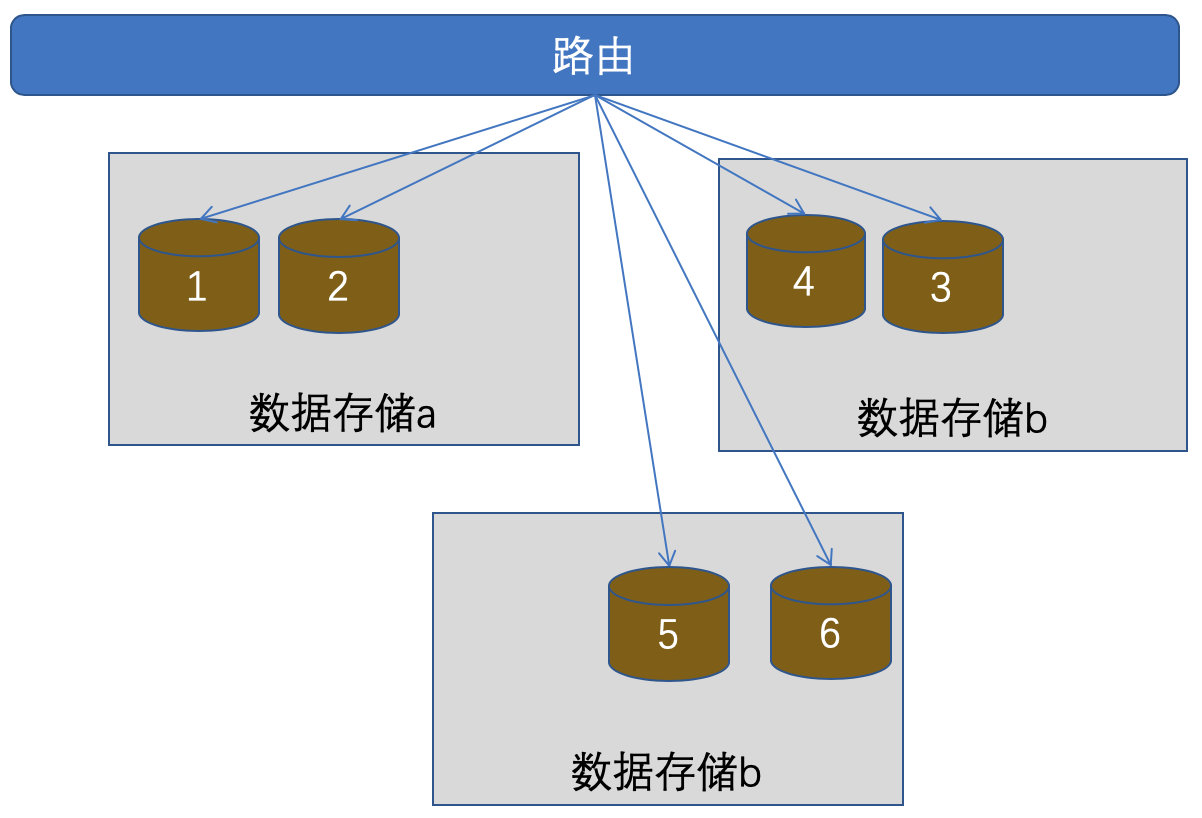
Redis/es/fastdfs,将数据按片切分:
1、切成6个片,每个片存储总量1/6数据
2、则两个库每个库分担三个片
3、若三个库,则每个库只需要承担两个片
4、路由管理,只记录数据与片柱的关系
此模式下,进行集群的动态扩容时,可以采用多种扩容的方法。
- hash方式,根据记录(或者对象)的关键值将记录映射到表中的一个槽。
缺点:当加入或者删除一个节点的时候,大量的数据需要移动。当原始数据的特征值分布不均匀时,会导致大量的数据集中到一个物理节点上。
- 一致性Hash,将数据按照特征值映射到一个首尾相接的hash环上,同时也将节点(按照IP地址或者机器名hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。通过引入虚拟节点,达到负载均衡的效果。
Dynamo、Cassandra都使用了一致性hash算法,且在比较高的版本中都使用了虚拟节点的概念。
- range based,就是按照关键值划分成不同的区间,每个物理节点负责一个或者多个区间。其实这种方式跟一致性hash有点像,可以理解为物理节点在hash环上的位置是动态变化的。
注意,区间的大小不是固定的,每个数据区间的数据量与区间的大小也是没有关系的。比如说,一部分数据非常集中,那么区间大小应该是比较小的,即以数据量的大小为片段标准。在实际工程中,一个节点往往负责多个区间,每个区间成为一个块(chunk、block),每个块有一个阈值,当达到这个阈值之后就会分裂成两个块。这样做的目的在于当有节点加入的时候,可以快速达到均衡的目的。
本文由『后端精进之路』原创,首发于博客 http://teckee.github.io/ , 转载请注明出处
搜索『后端精进之路』关注公众号,立刻获取最新文章和价值2000元的BATJ精品面试课程。
