最近系统被扫出来还在使用老旧的log4j,需要升级到最新的log4j。但是在升级的发现,Java相关的日志处理库有log4j, log4j2,slf4j和logback,初一看确实有点头大,那么区别是啥呢?之前也大概知道一些,查找了大量相关资料,这里好好总结一下,相信你读完就会熟练掌握

Log4J、Log4J2和LogBack的历史故事
使用过Log4J和LogBack的同学肯定能发现,这两个框架的设计理念极为相似,使用方法也如出一辙。其实这个两个框架的作者都是一个人,Ceki Gülcü,俄罗斯程序员。
Log4J 最初是基于Java开发的日志框架,发展一段时间后,作者Ceki Gülcü将Log4j捐献给了Apache软件基金会,使之成为了Apache日志服务的一个子项目。 又由于Log4J出色的表现,后续又被孵化出了支持C, C++, C#, Perl, Python, Ruby等语言的子框架。
然而,伟大的程序员好像都比较有个性。Ceki Gülcü由于不满Apache对Log4J的管理,决定不再参加Log4J的开发维护。“出走”后的Ceki Gülcü另起炉灶,开发出了LogBack这个框架(SLF4J是和LogBack一起开发出来的)。LogBack改进了很多Log4J的缺点,在性能上有了很大的提升,同时使用方式几乎和Log4J一样,许多用户开始慢慢开始使用LogBack。
由于受到LogBack的冲击,Log4J开始式微。终于,2015年9月,Apache软件基金业宣布,Log4j不在维护,建议所有相关项目升级到Log4j2。Log4J2是Apache开发的一个新的日志框架,改进了很多Log4J的缺点,同时也借鉴了LogBack,号称在性能上也是完胜LogBack。性能这块后面我会仔细分析。
那slf4j和这些有什么关系?
SLF4J的全称是Simple Logging Facade for Java,slf4j是门面模式的典型应用,因此在讲slf4j前,需要简单介绍下门面模式。
看看门面模式再说
下面是门面模式的一个典型调用过程,其核心为外部与一个子系统的通信必须通过一个统一的外观对象进行,使得子系统更易于使用。 下图中客户端不需要直接调用几个子系统,只需要与统一的门面进行通信即可。
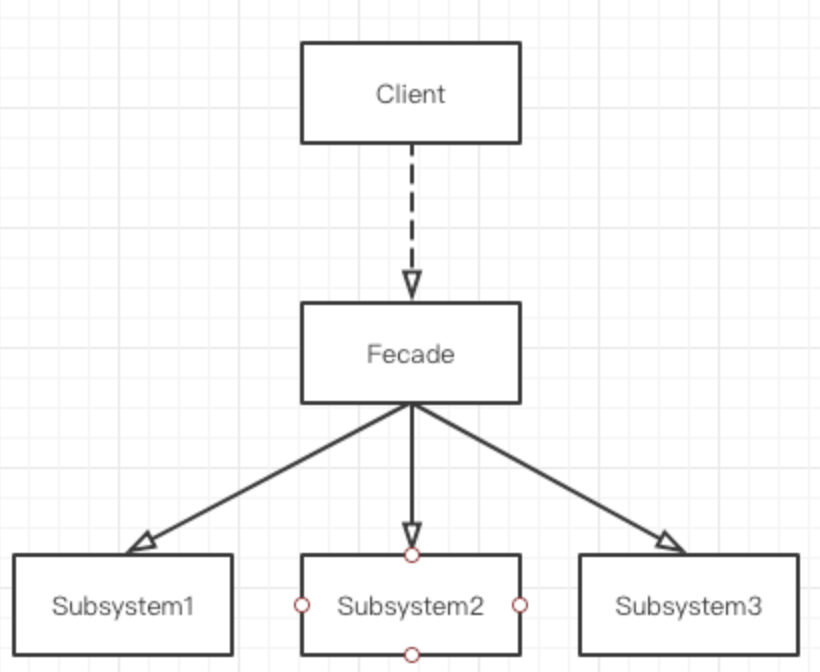
门面模式的核心为Facade即门面对象,核心为几个点:
- 知道所有子角色的功能和责任。
- 将客户端发来的请求委派到子系统中,没有实际业务逻辑。
- 不参与子系统内业务逻辑的实现。
为什么要使用slf4j ?
回答这个问题之前,我们先看看如果需要用上面几个日志框架来打印日志,一般怎么做,具体代码如下:
1 | // 使用log4j,需要log4j.jar |
从上面不难看出,使用不同的日志框架,就要引入不同的jar包,使用不同的代码获取Logger。如果项目升级需要更换不同的框架,那么就需要修改所有的地方来获取新的Logger,这将会产生巨大的工作量。
基于此,我们需要一种接口来将不同的日志框架的使用统一起来,这也是为什么要使用slf4j的原因。
SLF4J,即简单日志门面(Simple Logging Facade for Java),不是具体的日志解决方案,它只服务于各种各样的日志系统。按照官方的说法,SLF4J是一个用于日志系统的简单Facade,允许最终用户在部署其应用时使用其所希望的日志系统。
注意:类似的日志门面还有Jakarta Common logging(JCL),主要区别在于,SLF4J是一个比较新的日志框架,它更加灵活,性能更好,支持更多的日志实现,而且JCL基于classLoader在运行时动态加载日志框架,可能会产生很多意想不到的安全问题,关于这个问题可以参考讨论https://stackoverflow.com/questions/3222895/what-is-the-issue-with-the-runtime-discovery-algorithm-of-apache-commons-logging
通过上面的介绍,我们可以知道JCL和SLF4J都是日志门面(Facade),而Log4J、Log4J2和LogBack都是子系统角色(SunSystem),也就是具体的日志实现框架。他们的关系如下,JUL是JDK本身提供的一种实现。
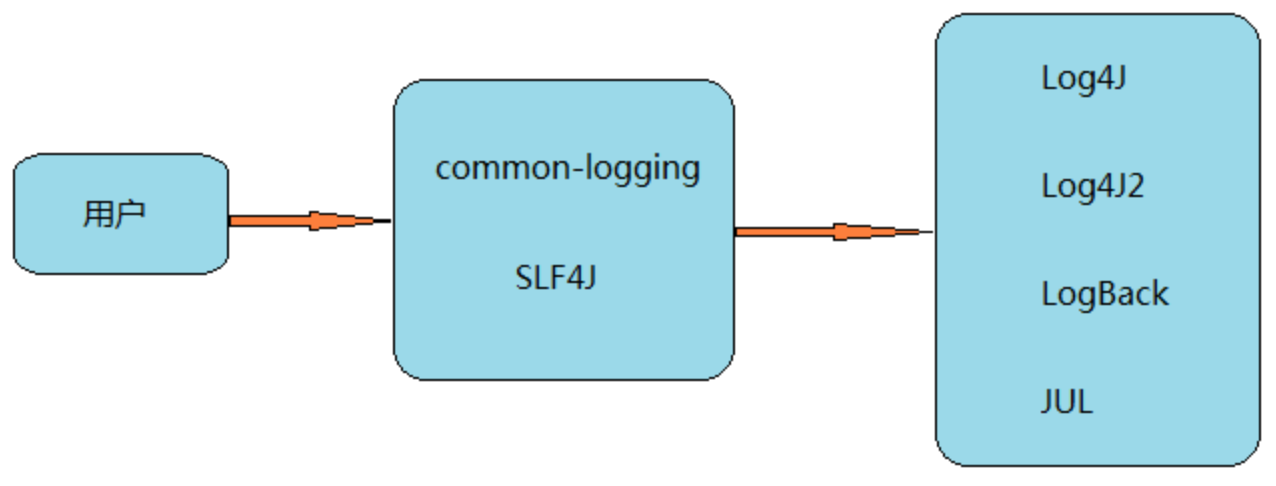
使用日志门面引入日志组件的最大优势是:将系统和具体的日志实现框架解耦合。
slf4j怎么和日志框架结合使用?
使用slf4j后,当我们在打印日志时,就可以使用下面的方式:
1 | import org.slf4j.Logger; |
这又引入了另外一个问题,slf4j如何决定使用哪个框架日志呢,并且引入哪些jar包呢?官方为我们准备了下面的组合依赖结构图:
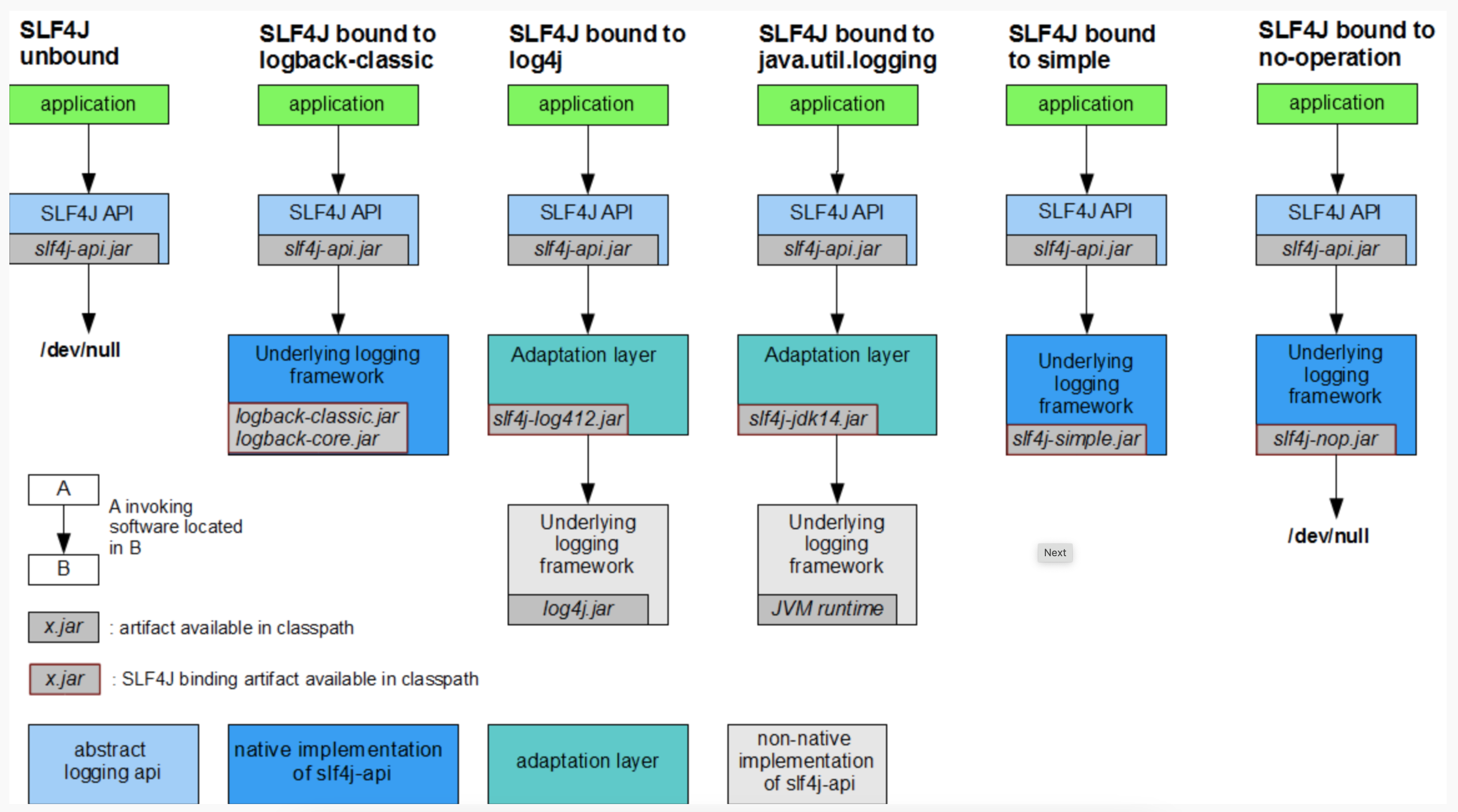
总结来说,就是一下几种:
- slf4j + logback: slf4j-api.jar + logback-classic.jar + logback-core.jar
- slf4j + log4j: slf4j-api.jar + slf4j-log412.jar + log4j.jar
- slf4j + jul: slf4j-api.jar + slf4j-jdk14.jar
- 也可以只用slf4j无日志实现:slf4j-api.jar + slf4j-nop.jar
注意到这里没有log4j2依赖jar的关系,和log4j2配合需要导入log4j2的log4j-api.jar、log4j-core.jar和桥接包log4j-slf4j-impl.jar。
所谓的桥接包,就是实现StaticLoggerBinder类,用来连接slf4j和日志框架。因为log4j和log4j2刚开始没有StaticLoggerBinder这个类,为了不改变程序结构,只能重新写一个新的jar来实现StaticLoggerBinder。而logback出现slf4j之后,于是在logback本身的jar中实现了StaticLoggerBinder,所以就不需要桥接包。
现在为什么推荐Log4j2?
Apache Log4j 2 是 Log4j(1) 的升级版,比它的祖先 Log4j 1.x和logback 有了很大的改进。除了内部设计的调整外,主要有以下几点的大升级:
- 更简化的配置
- 更强大的参数格式化
- 最夸张的异步性能
Log4j2 中,分为 API(log4j-api)和实现 (log4j-core) 两个模块。API 和 slf4j 是一个类型,属于日志抽象 / 门面,而实现部分,才是 Log4j 2 的核心。
- org.apache.logging.log4j » log4j-api
- org.apache.logging.log4j » log4j-core
log4j2 在目前 JAVA 中的日志框架里,异步日志的性能是最高的,具体可以看下面的对比图:
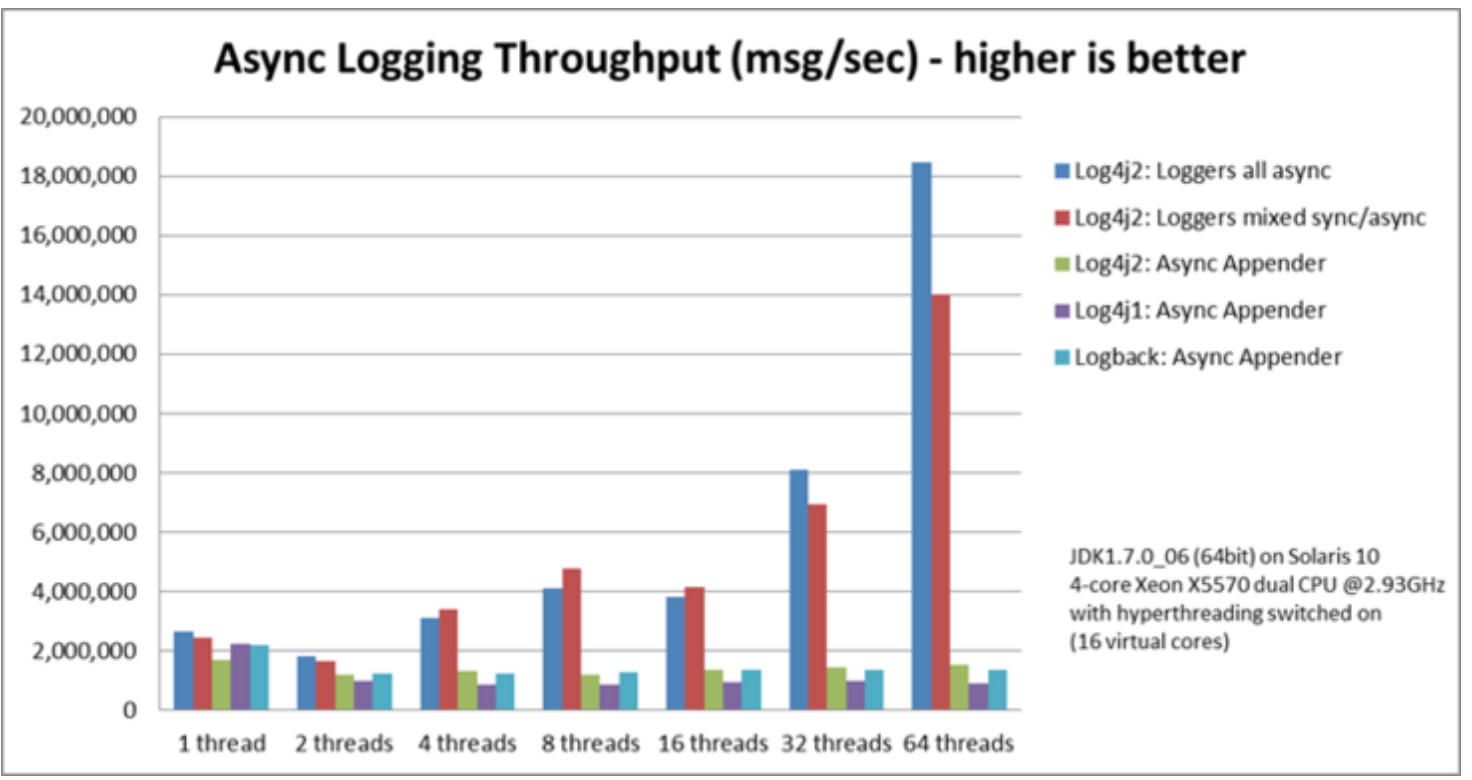
log4j2采用了字符串复用等手段来实现零GC模式运行,另外提供了MemoryMappedFileAppender实现了极高的IO性能,而且API相比slf4j,有更丰富的参数格式化功能。
怎么使用Log4j2?
说了半天,那怎么去使用Log4j2呢,这部分我仔细介绍一下。
常规使用步骤
下面以Maven配置为例进行介绍。
- 首先需要加入log4j的依赖,注意2.17.1以下的版本会有远程代码执行的安全漏洞,具体参考Apache官方文档(https://logging.apache.org/log4j/2.x/security.html)。推荐使用最新的版本。
1 | <dependency> |
- 配置好log4j2.xml配置文件,并放到项目的classpath里面,一般会放到resources目录里面。下面是一个参考的配置,当然也可以使用properties文件和yaml文件来进行配置。
1 |
|
- 在程序中打印log。使用下面的方式来打印log即可。
1 | import org.apache.logging.log4j.LogManager; |
输出如下:
1 |
|
配置文件详解
首先给大家看一个比较全面的配置文件,可能看起来比较头大,不急我后面会一点点仔细分析。
1 |
|
下面为大家仔细解析这个配置文件,
1. 根节点
Configuration有两个属性:status和monitorinterval,有两个子节点:Appenders和Loggers(表明可以定义多个Appender和Logger)。
- status用来指定log4j本身的打印日志的级别.
- monitorinterval用于指定log4j自动重新配置的监测间隔时间,单位是s,最小是5s.
2. Appenders节点
Appenders节点,常见的子节点有:Console、RollingFile、File。
Console节点用来定义输出到控制台的Appender。
- name:指定Appender的名字。
- target:SYSTEM_OUT 或 SYSTEM_ERR,一般只设置默认:SYSTEM_OUT。
- PatternLayout:输出格式,不设置默认为:%m%n。
File节点用来定义输出到指定位置的文件的Appender。
- name:指定Appender的名字。
- fileName:指定输出日志的目的文件带全路径的文件名。
- PatternLayout:输出格式,不设置默认为:%m%n。
RollingFile节点用来定义超过指定大小自动删除旧的创建新的的Appender。
name:指定Appender的名字。
fileName:指定输出日志的目的文件带全路径的文件名。
PatternLayout:输出格式,不设置默认为:%m%n。
filePattern:指定新建日志文件的名称格式。
Policies是指定滚动日志的策略,就是什么时候进行新建日志文件输出日志。
TimeBasedTriggeringPolicy:Policies子节点,基于时间的滚动策略,interval属性用来指定多久滚动一次,默认是1 hour。modulate=true用来调整时间:比如现在是早上3am,interval是4,那么第一次滚动是在4am,接着是8am,12am…而不是7am。
SizeBasedTriggeringPolicy:Policies子节点,基于指定文件大小的滚动策略,size属性用来定义每个日志文件的大小。DefaultRolloverStrategy:用来指定同一个文件夹下最多有几个日志文件时开始删除最旧的,创建新的(通过max属性)。
3. Loggers
Loggers节点,常见子节点有:Root和Logger。
Root节点用来指定项目的根日志,如果没有单独指定Logger,那么就会默认使用该Root日志输出
- level:日志输出级别,共有8个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF。
- AppenderRef:Root的子节点,用来指定该日志输出到哪个Appender。
Logger节点用来单独指定日志的形式,比如要为指定包下的class指定不同的日志级别等。
- level:日志输出级别,共有8个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF。
- name:用来指定该Logger所适用的类或者类所在的包全路径,继承自Root节点。
- AppenderRef:Logger的子节点,用来指定该日志输出到哪个Appender,如果没有指定,就会默认继承自Root.如果指定了,那么会在指定的这个Appender和Root的Appender中都会输出,此时我们可以设置Logger的additivity=”false”只在自定义的Appender中进行输出。
4. 日志Level
共有8个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF。
- All:最低等级的,用于打开所有日志记录。
- Trace:是追踪,就是程序推进以下,你就可以写个trace输出,所以trace应该会特别多,不过没关系,我们可以设置最低日志级别不让他输出。
- Debug:指出细粒度信息事件对调试应用程序是非常有帮助的。
- Info:消息在粗粒度级别上突出强调应用程序的运行过程。
- Warn:输出警告及warn以下级别的日志。
- Error:输出错误信息日志。
- Fatal:输出每个严重的错误事件将会导致应用程序的退出的日志。
- OFF:最高等级的,用于关闭所有日志记录。
程序会打印高于或等于所设置级别的日志,设置的日志等级越高,打印出来的日志就越少。
参考范例
这部分给大家提供几个常用的配置,直接放到项目里面改一下包名就可以用。
1. 输出日志到Console
1 |
|
2. 输出日志到文件
1 |
|
3. 输出到文件并滚动生成新的日志文件
1 | <Configuration status="DEBUG"> |
以上就是所有的内容,看完下来就会搞清楚各种log框架的关系,以及如何在项目中使用这些log框架。
参考:
- https://mkyong.com/logging/apache-log4j-2-tutorials/
- https://www.zybuluo.com/wxf/note/1349992
- https://www.cnblogs.com/xrq730/p/8619156.html
- https://www.cnblogs.com/54chensongxia/p/12321446.html
- https://segmentfault.com/a/1190000039751787
- https://juejin.cn/post/7033021644142542878
可以关注公众号【码老师】,一时间获取最通俗易懂的原创技术干货。
本文由『码老思』原创,首发于博客 http://teckee.github.io/ , 转载请注明出处
