
5 并发容器
5.1 Hashtable、HashMap、TreeMap、HashSet、LinkedHashMap
在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比。
Hashtable、HashMap、TreeMap 都是最常见的一些 Map 实现,是以键值对的形式存储和操作数据的容器类型。
Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户 ID 和用户信息对应的运行时存储结构。
HashMap 明确声明不是线程安全的数据结构,如果忽略这一点,简单用在多线程场景里,难免会出现问题,如 HashMap 在并发环境可能出现无限循环占用 CPU、size 不准确等诡异的问题。
TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
Hashtable
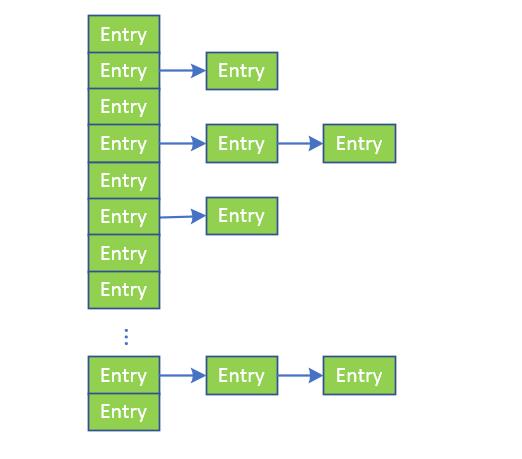
Hashtable是通过”拉链法”实现的哈希表,结构如下图所示:
1. 定义
1 | public class Hashtable<K,V> |
Hashtable 继承于 Dictionary 类,实现了 Map, Cloneable, java.io.Serializable接口。
2. 构造方法
Hashtable 一共提供了 4 个构造方法:
1 | public Hashtable(int initialCapacity, float loadFactor): 用指定初始容量和指定负载因子构造一个新的空哈希表。 |
它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
- table 是一个 Entry[] 数组类型,而 Entry实际上就是如上图所示的一个单向链表。Hashtable的键值对都是存储在Entry数组中的。
- count 是 Hashtable 的大小,它是 Hashtable 保存的键值对的数量。
- threshold 是 Hashtable 的阈值,用于判断是否需要调整 Hashtable 的容量。threshold 的值=”容量 x 负载因子”。
- loadFactor 就是负载因子。
- modCount 记录hashTable被修改的次数,在对HashTable的操作中,无论add、remove、clear方法只要是涉及了改变Table数组元素的个数的方法都会导致modCount的改变。这主要用来实现“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。
fail-fast机制举例:有两个线程(线程A,线程B),其中线程A负责遍历list、线程B修改list。线程A在遍历list过程的某个时候(此时expectedModCount = modCount=N),线程启动,同时线程B增加一个元素,这是modCount的值发生改变(modCount + 1 = N + 1)。线程A继续遍历执行next方法时,通告checkForComodification方法发现expectedModCount = N ,而modCount = N + 1,两者不等,这时就抛出ConcurrentModificationException 异常,从而产生fail-fast机制。
3. PUT操作
put 方法的整个流程为:
- 判断 value 是否为空,为空则抛出异常;
- 计算 key 的 hash 值,并根据 hash 值获得 key 在 table 数组中的位置 index,如果 table[index] 元素不为空,则进行迭代,如果遇到相同的 key,则直接替换,并返回旧 value;
- 否则,我们可以将其插入到 table[index] 位置。
1 | public synchronized V put(K key, V value) { |
4. Get操作
首先通过 hash()方法求得 key 的哈希值,然后根据 hash 值得到 index 索引。然后迭代链表,返回匹配的 key 的对应的 value;找不到则返回 null。
1 | public synchronized V get(Object key) { |
5. rehash扩容
- 数组长度增加一倍(如果超过上限,则设置成上限值)。
- 更新哈希表的扩容门限值。
- 遍历旧表中的节点,计算在新表中的index,插入到对应位置链表的头节点。
1 | protected void rehash() { |
6. Remove方法
remove方法主要逻辑如下:
- 先获取synchronized锁。
- 计算key的哈希值和index。
- 遍历对应位置的链表,寻找待删除节点,如果存在,用e表示待删除节点,pre表示前驱节点。如果不存在,返回null。
- 更新前驱节点的next,指向e的next。返回待删除节点的value值。
Hash值的不同实现:JDK7 Vs JDK8
以上给出的代码均为jdk7中的实现,注意到在jdk7和8里面,关于元素hash值的计算方法是不一样的。
- 在JDK7中,hashtable专门实现了hash函数,在以上的例子中都有看到,具体的实现如下:
1 | //利用异或,移位等运算,对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀 |
以上hash函数计算出的值,通过indexFor进一步处理来获取实际的存储位置
1 | //返回数组下标 |
- 在jdk8里面,直接调用key.hashCode()来获取key的hash值,接着在保证hash值为正数的前提下,得到相应的下标,
1 | int hash = key.hashCode(); |
注意到都使用到了hashCode,这个方法是在Object方法中定义的,
1 | @HotSpotIntrinsicCandidate |
可以看到是Object里没有给出hashCode的实现,只是声明为一个native方法,说明Java会去调用本地C/C++对hashcode的具体实现。
在JDK8及以后,可以通过如下指令来获取到所有的hash算法,
1 | java -XX:+PrintFlagsFinal | grep hashCode |
具体大概有如下几种,第5个算法是默认使用的,用到了异或操作和一些偏移算法来生成hash值。
0 == Lehmer random number generator,
1 == “somehow” based on memory address
2 == always 1
3 == increment counter
4 == memory based again (“somehow”)
5 == Marsaglia XOR-Shift algorithm, that has nothing to do with memory.
HashTable相对于HashMap的最大特点就是线程安全,所有的操作都是被synchronized锁保护的
参考:
- https://www.imooc.com/article/23015
- https://wiki.jikexueyuan.com/project/java-collection/hashtable.html
- https://stackoverflow.com/questions/49172698/default-hashcode-implementation-for-java-objects
HashMap
HashMap是java中使用最为频繁的map类型,其读写效率较高,但是因为其是非同步的,即读写等操作都是没有锁保护的,所以在多线程场景下是不安全的,容易出现数据不一致的问题。
HashMap的结构和HashTable一致,都是使用是由数组和链表两种数据结构组合而成的,不同的是在JDK8里面引入了红黑树,当链表长度大于8时,会将链表转换为红黑树。
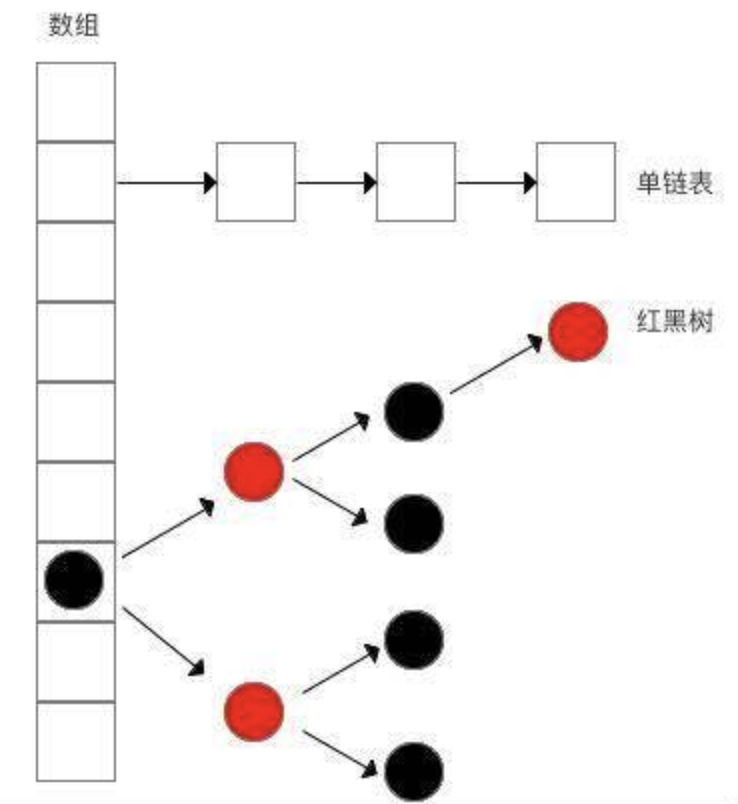
HashMap的成员变量和HashTable一样,在进行初始化的时候,都会设置一个容量值(capacity)和加载因子(loadFactor)。
- 容量值指的并不是表的真实长度,而是用户预估的一个值,真实的表长度,是不小于capacity的2的整数次幂。
- 加载因子是为了计算哈希表的扩容门限,如果哈希表保存的节点数量达到了扩容门限,哈希表就会进行扩容的操作,扩容的数量为原表数量的2倍。默认情况下,capacity的值为16,loadFactor的值为0.75(综合考虑效率与空间后的折衷)
HashMap的核心构造函数如下,主要是设置负载因子,以及根据用户的设定容量,找到一个不小于该容量的阈值。
1 | public HashMap(int initialCapacity, float loadFactor) { |
由于HashMap和HashTable有实现上有诸多相似之处,这里会重点介绍hashMap在jdk7和8中的不同实现。
Hash运算
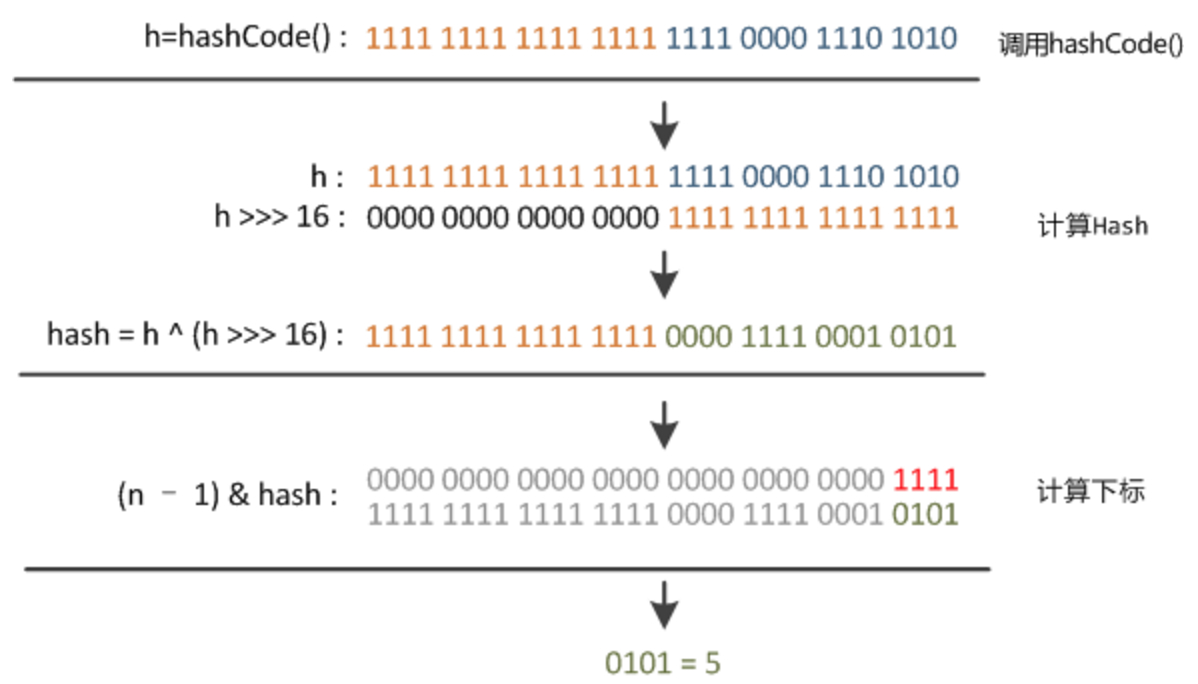
不管增加、删除、查找键值对,定位到哈希桶数组的位置都是很关键的第一步。都需要用到hash算法,jdk7和8中的算法基本一致,具体实现如下:
1 | static final int hash(Object key) { //jdk1.8 & jdk1.7 |
然后利用得到的hash值与数组长度取模,得到相应的index。
以下图示实例,给出了计算过程,
Get操作
1 | public V get(Object key) { |
Get操作比较简单:
- 先定位到数组中index位置,检查第一个节点是否满足要求
- 遍历对应该位置的链表,找到满足要求节点进行return
PUT操作
PUT操作的执行过程如下:
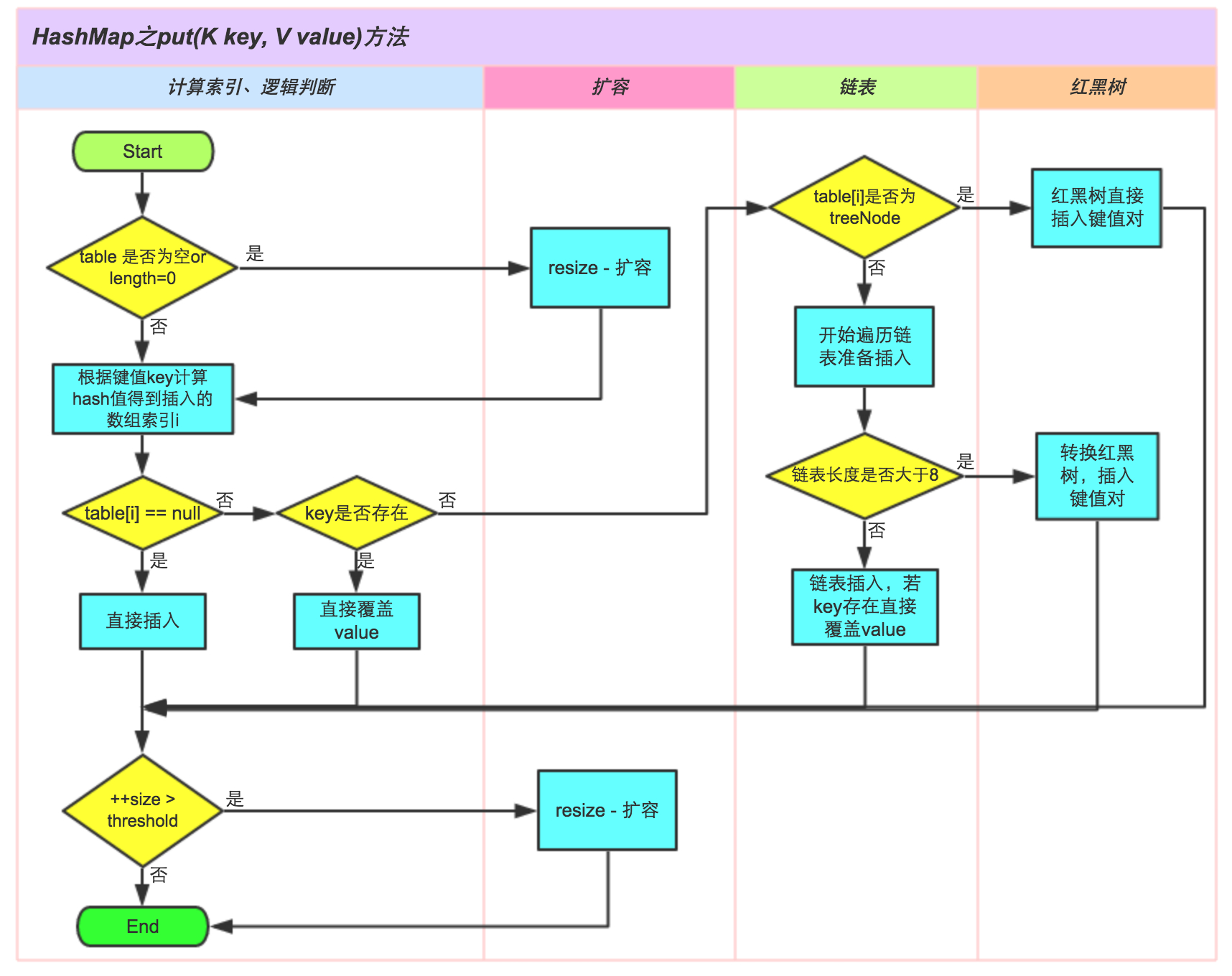
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
1 | 1 public V put(K key, V value) { |
Resize扩容操作
由于JDK8引入了红黑树,所以在实现上JDK7和8的resize过程不太一致。
首先是JDK7的实现,
1 | 1 void resize(int newCapacity) { //传入新的容量 |
这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
1 | 1 void transfer(Entry[] newTable) { |
newTable[i]的引用赋给了e.next,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到Entry链的尾部(如果发生了hash冲突的话),这一点和Jdk1.8有区别。
具体举例如下图所示:
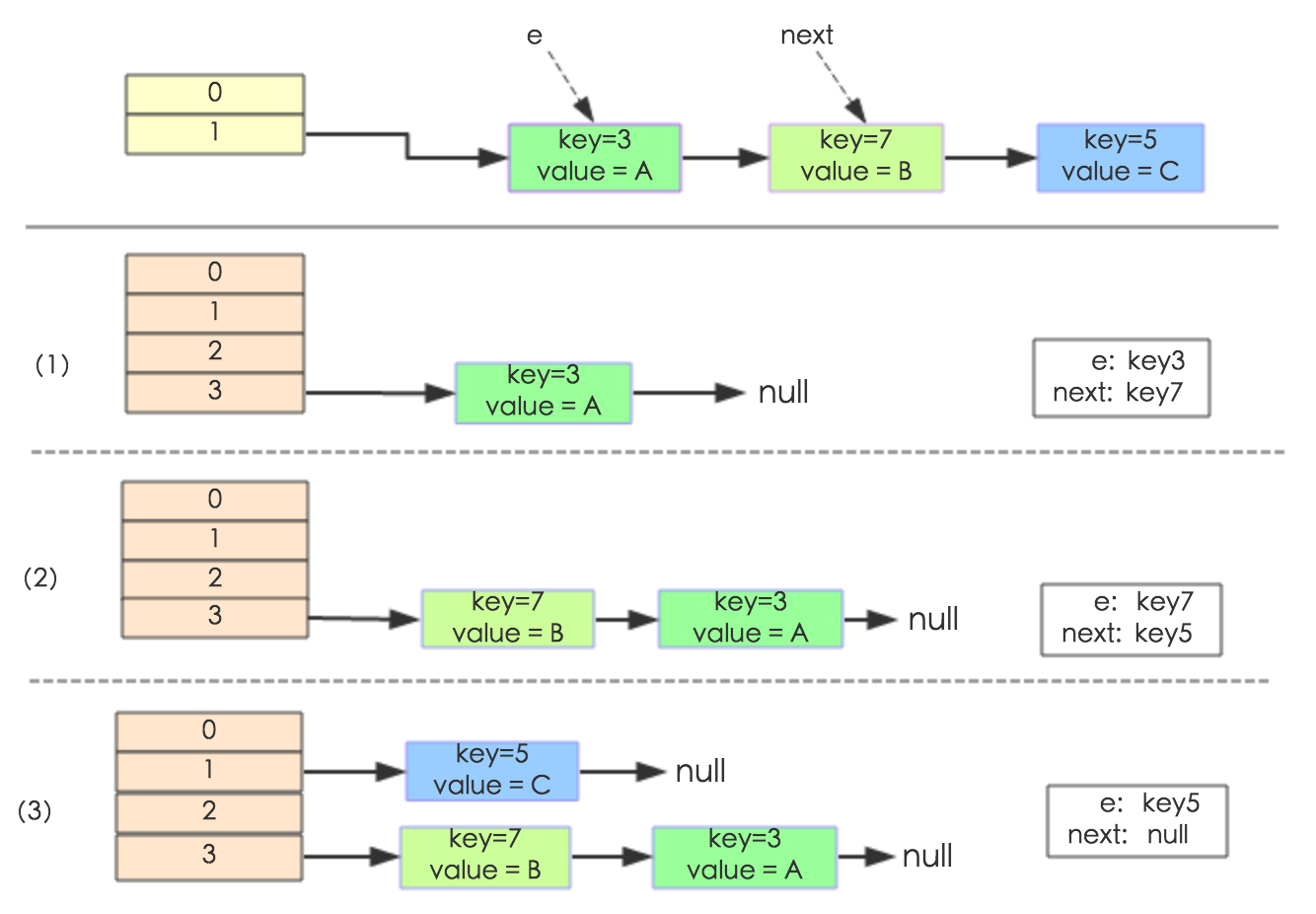
接下来是JDK8中的实现,
1 | /** |
由于Size会进行2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。通过下面的例子,可以清楚的看到,21和5在原来的数组中都处于相同的位置,但是在新的数组中,21到了新的位置,位置为原来的位置加上16,也就是旧的Capacity;但是5还在原来的位置。
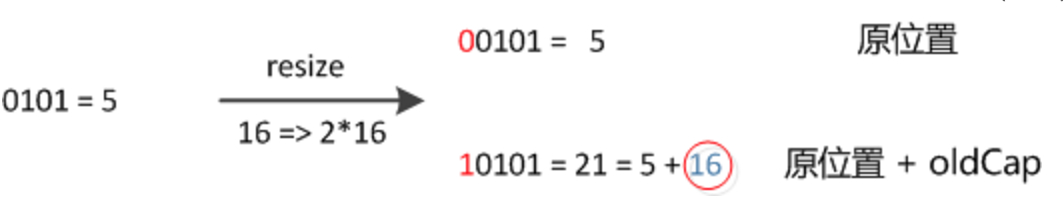
假定我们在Size变为2倍以后,重新计算hash,因为n变为2倍,相应的n-1的mask范围在高位多1bit(红色),也就是与上面示意图中红色部分对应的那一位,如果那位是1,则需要移动到新的位置,否则不变。
回到代码实现中,直接用旧的hash值与上oldCapacity,因为旧的capacity是2的倍数(二进制为00000…1000),而且获取旧index的时候采用hash&(oldCap-1),所以直接e.hash & oldCap就是判断新增加的高位是否为1,为1则需要移动,否则保持不变。
1 | if ((e.hash & oldCap) == 0) |
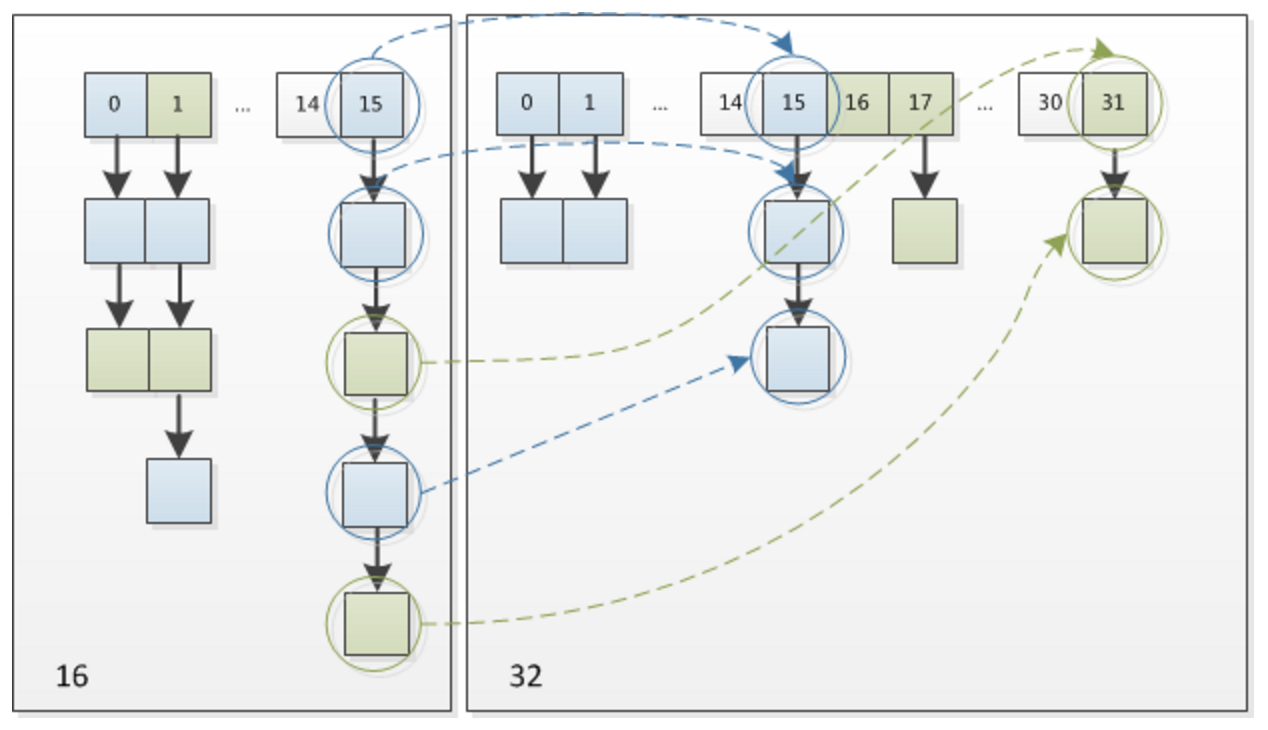
这种巧妙的方法,同时由于高位的1和0随机出现,保证了resize之后元素分布的离散性。
下图是这一过程的模拟,
JDK8中的红黑树
引入红黑树主要是为了保证在hash分布极不均匀的情况下的性能,当一个链表太长(大于8)的时候,通过动态的将它替换成一个红黑树,这话的话会将时间复杂度从O(n)降为O(logn)。
为什么HashMap的数组长度一定保持2的次幂?
- 从上面的分析JDK8 resize的过程可以可能到,数组长度保持2的次幂,当resize的时候,为了通过h&(length-1)计算新的元素位置,可以看到当扩容后只有一位差异,也就是多出了最左位的1,这样计算 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致,否则index+OldCap。
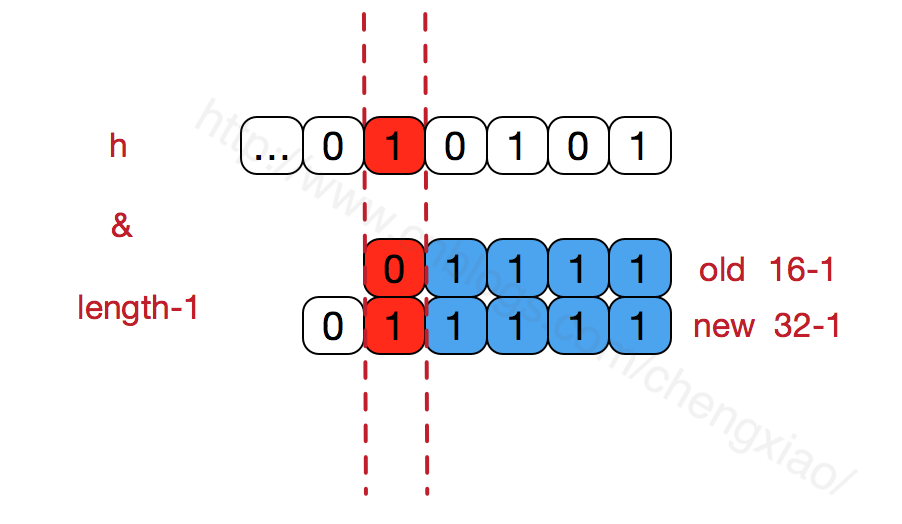
- 数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀。hash函数采用各种位运算也是为了使得低位更加散列,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,可以尽可能的使元素分布比较均匀。
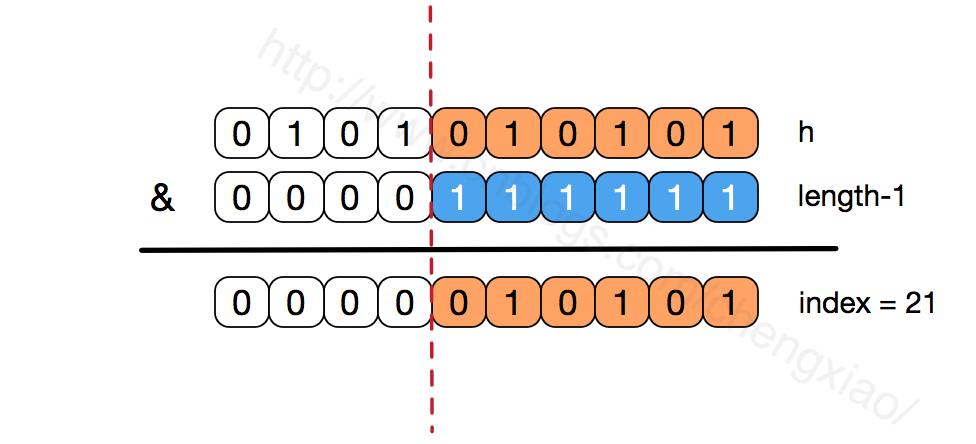
HashMap Vs HashTable
- HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
- HashTable 继承自 Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现。
- HashTable 的方法是 Synchronized 的,而 HashMap 不是,在多个线程访问 Hashtable 时,不需要自己为它的方法实现同步,而 HashMap 就必须为之提供外同步。
参考:
- https://tech.meituan.com/2016/06/24/java-hashmap.html
- https://juejin.im/post/5aa5d8d26fb9a028d2079264
- https://my.oschina.net/hosee/blog/618953
- https://www.imooc.com/article/22943
- https://www.cnblogs.com/chengxiao/p/6059914.html
TreeMap
TreeMap继承于AbstractMap,实现了Map, Cloneable, NavigableMap, Serializable接口。
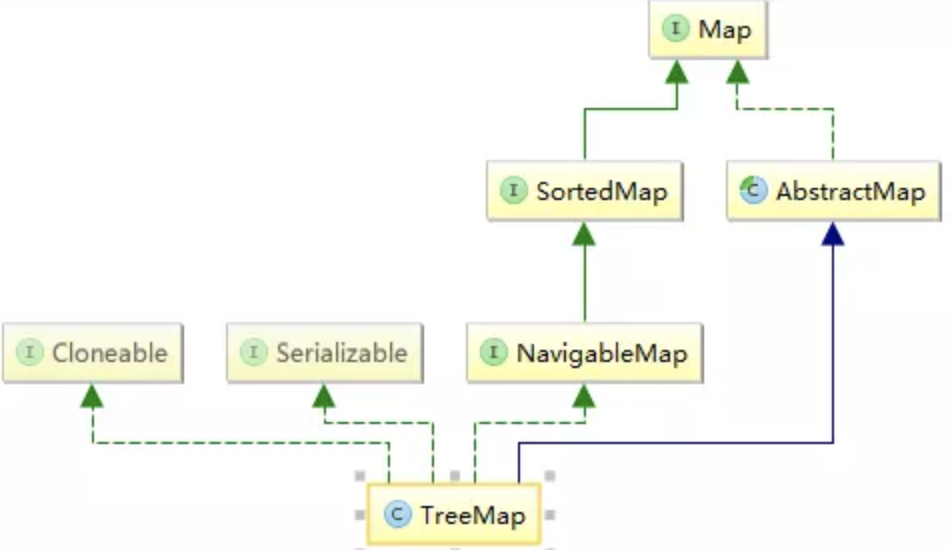
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
对于SortedMap来说,该类是TreeMap体系中的父接口,也是区别于HashMap体系最关键的一个接口。SortedMap接口中定义的第一个方法Comparator<? super K> comparator();该方法决定了TreeMap体系的走向,有了比较器,就可以对插入的元素进行排序了。
TreeMap的查找、插入、更新元素等操作,主要是对红黑树的节点进行相应的更新,和数据结构中类似。
TreeSet
TreeSet基于TreeMap实现,底层也是红黑树。只是每次插入元素时,value为一个默认的dummy数据。
HashSet
HashSet的实现很简单,内部有一个HashMap的成员变量,所有的Set相关的操作都转换为了对HashMapde操作。
1 | public class HashSet<E> |
从上面的code可以看到,内部还定义了一个PRESENT的dummy对象,当添加元素时,直接添加一对键值对,key为元素值,value为PRESENT。
1 | /** |
其他的操作类似,就是把PRESENT当做value。
LinkedHashMap
首先是定义,
1 | public class LinkedHashMap<K,V> |
可以看到,LinkedHashMap是HashMap的子类,但和HashMap的无序性不一样,LinkedHashMap通过维护一个运行于所有条目的双向链表,保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序,这个可以在初始化的时候确定,默认采用插入顺序来维持取出键值对的次序。
在成员变量上,与HashMap不同的是,引入了before和after两个变量来记录前后的元素。
1 | 1、K key |
1-4是从HashMap.Entry中继承过来的;5-6是LinkedHashMap独有的。注意next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
可以把LinkedHashMap的结构看成如下图所示:
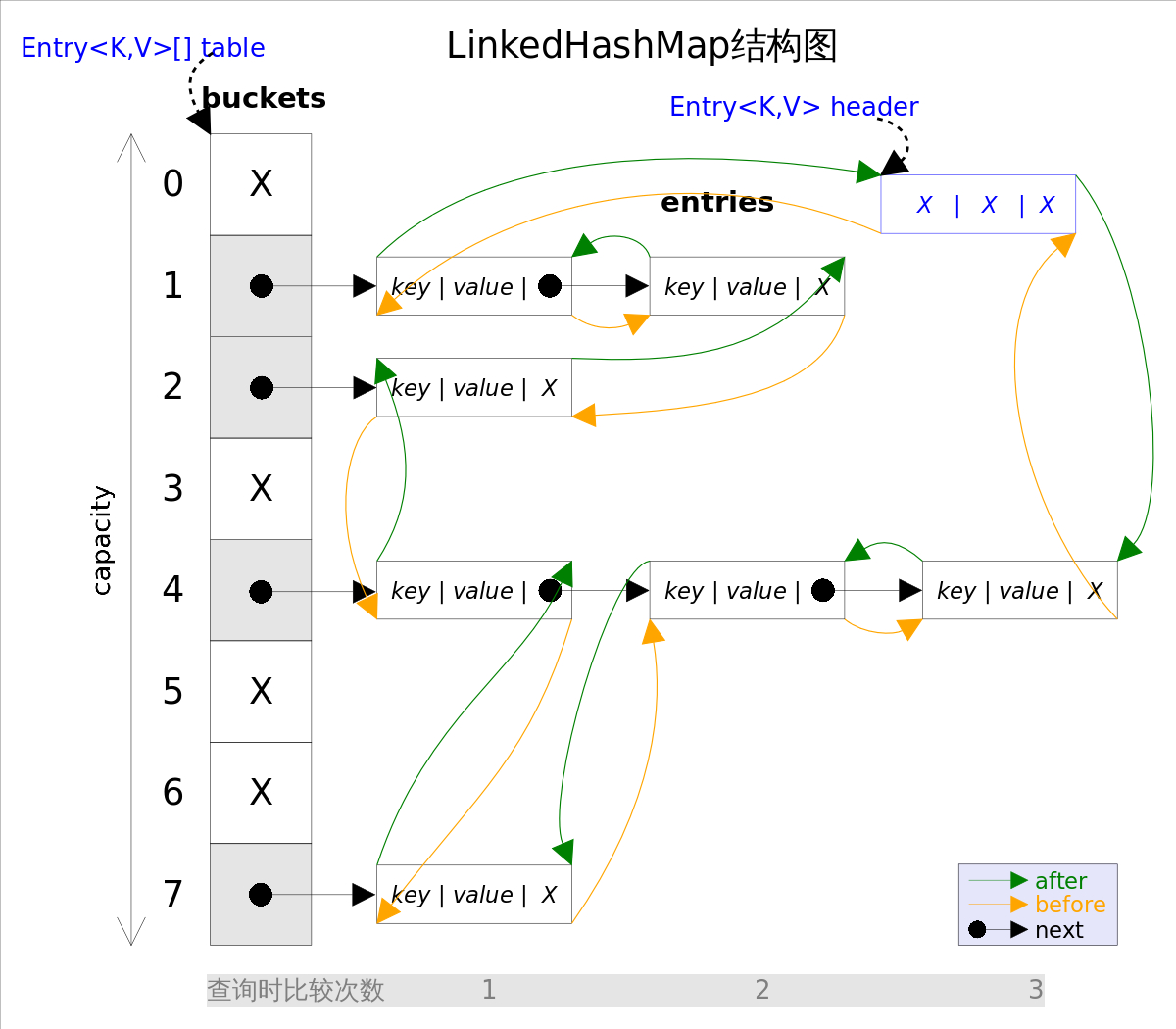
接下来主要介绍LinkedHashMap的排序操作,
在构造函数中,需要指定accessOrder,有两种情况:
- false,所有的Entry按照插入的顺序排列
- true,所有的Entry按照访问的顺序排列
1 | public LinkedHashMap(int initialCapacity, |
第二种情况,也就是accessOrder为true时,每次通过get/put方法访问时,都把访问的那个数据移到双向队列的尾部去,也就是说,双向队列最头的那个数据就是最不常访问的那个数据。具体实现如下,afterNodeAccess这个方法在HashMap中没有实现,LinkedHashMap进行了实现,将元素进行排序。
1 | void afterNodeAccess(Node<K,V> e) { // move node to last |
利用LinkedHashMap实现LRU缓存
LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。LinkedHashMap正好满足这个特性,当我们开启accessOrder为true时,最新访问(get或者put(更新操作))的数据会被丢到队列的尾巴处,那么双向队列的头就是最不经常使用的数据了。
此外,LinkedHashMap还提供了一个方法,这个方法就是为了我们实现LRU缓存而提供的,removeEldestEntry(Map.Entry<K,V> eldest) 方法。该方法可以提供在每次添加新条目时移除最旧条目的实现程序,默认返回 false。
下面是一个最简单的LRU缓存的实现,当size超过maxElement时,每次新增一个元素时,就会移除最久远的元素。
1 | public class LRUCache extends LinkedHashMap |
参考:
5.2 ConcurrentHashMap
这节开始介绍并发容器,首先是ConcurrentHashMap,实现了线程安全的HashMap。之前也提到了HashMap在多线程环境下的问题,这小节先详细分析为什么HashMap多线程下不安全。
HashMap多线程环境下的问题分析
首先说结论,为什么HashMap不是线程安全的?在多线程下,会导致HashMap的Entry链表形成环形数据结构,一旦形成环形,Entry的next节点永远不为空,无论是进行resize还是get/size等操作时,就会产生死循环。
首先针对JDK7进行分析:
下面是resize部分的代码,这段代码将原HashMap中的元素依次移动到扩容后的HashMap中,
1 | 1: // Transfer method in java.util.HashMap - |
在正常单线程的情况下,如果有如下的HashMap的结构,为了方便这里只有2个bucket(java.util.HashMap中默认是 16)。
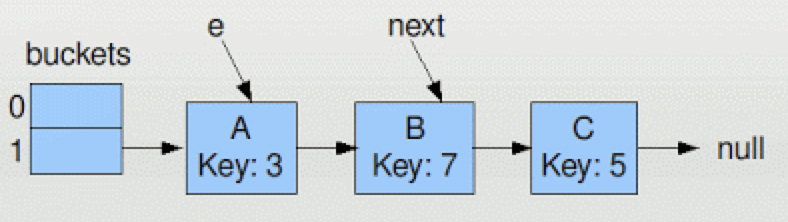
按照上面的resize流程,e和next分别指向A和B,A是第一次迭代将会被移动的元素,B是下一个。
- 第一次迭代后,A被移动到新的Map中,Map的容量已经增大了一倍。A的位置如下图所示
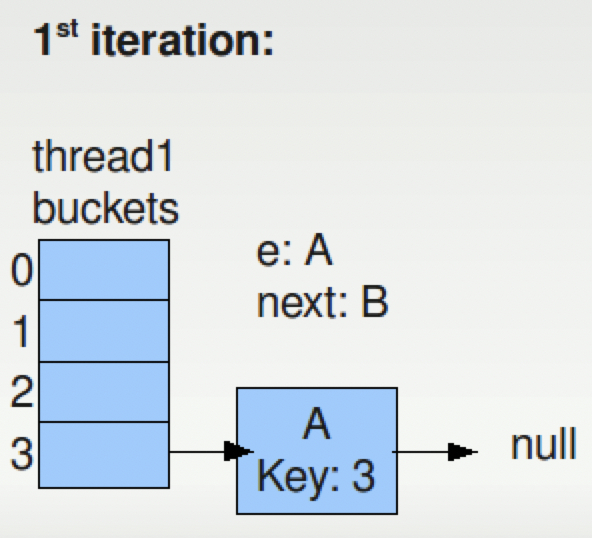
- 第二次迭代后,B被移动到了新的位置,如下图所示,C为下一个待移动的元素。
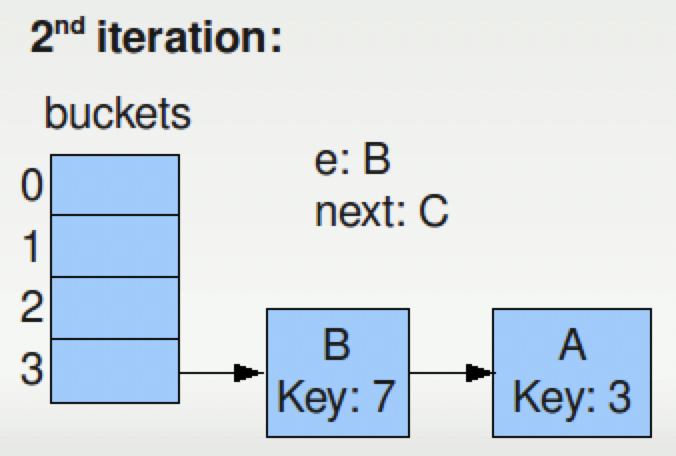
- 第三次迭代之后,C被移动到了新的位置,由于C之后没有其他元素,因此整个resize过程完成,最后新的Map如下:

在resize完成之后,每个bucket的深度变小了,达到了resize的目的。整个过程在单线程下没有任何问题,但是考虑到多线程的情况,就会可能会出现竞争。
现在有两个线程Thread1,Thread2同时进行resize的操作,假设Thread1在运行到第9行后,Thread2获取了CPU并且也开始执行resize的操作。
1 | 1: // Transfer method in java.util.HashMap - |
Thread1运行后,对应的e1和next1别指向A和B,但是Thread1并没有移动元素。
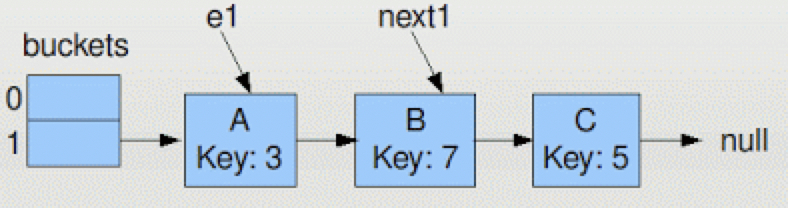
假设Thread2在获取CPU后完整的运行了整个resize,新的Map结构将会如下图所示:
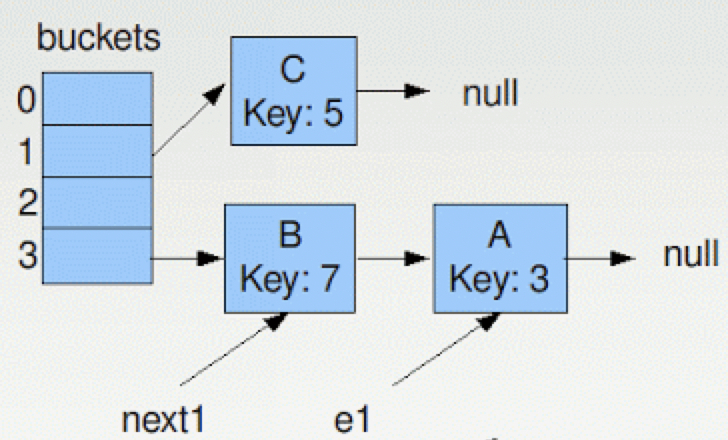
注意到e1和next1还是指向A和B,但是A和B的位置关系已经变了,按照resize的算法进行两轮迭代之后,变成如下的结构,
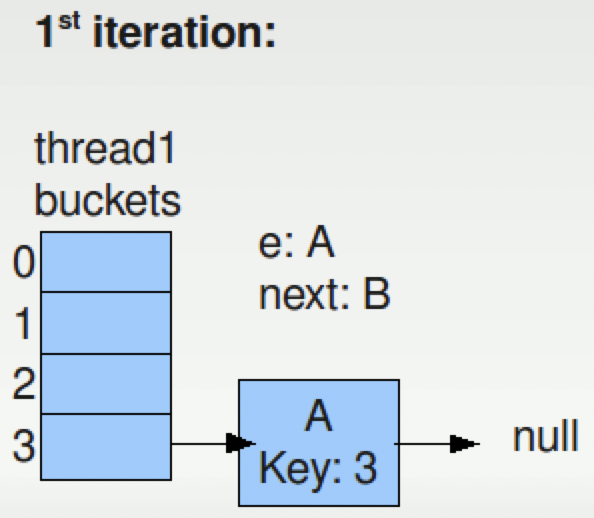
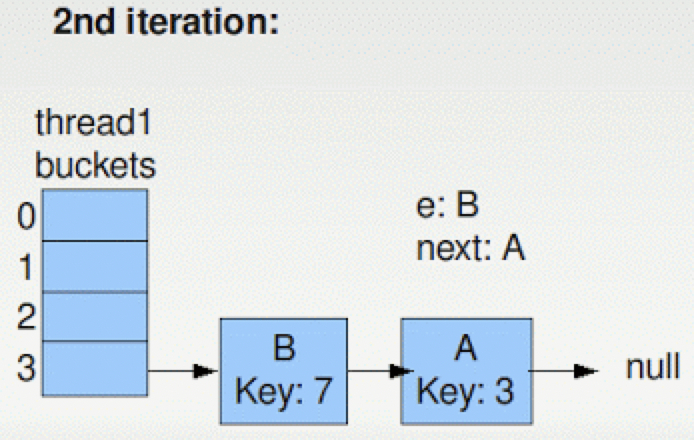
注意此时e和next的指向,在下一次的迭代中,将把A放在第3个bucket的一个位置,但是B仍然是指向A的,所以出现了下面的类似于双向链表的结构,
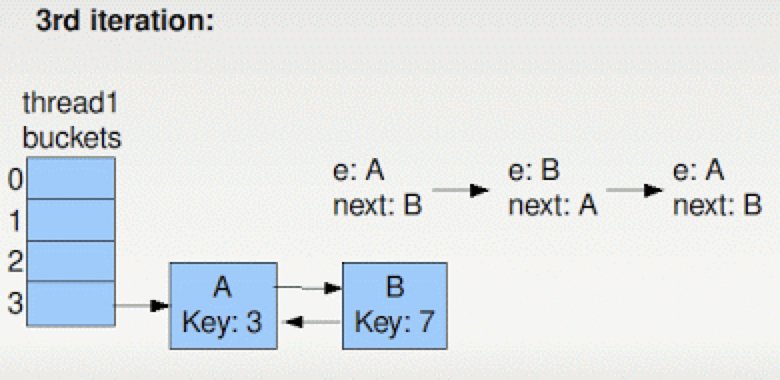
接着Thread1就会进入到无限循环中,此时如果有get操作的话,也会出现无限循环的情况。这就是HashMap在多线程情况下容易出现的问题。
接着针对JDK8进行分析:
前面已经提到,JDK8和7在Resize的不同之处就是8保留了链表中元素的先后位置,这样基本可以确保在resize过程中不出现循环的问题,但是还是可能出现数据丢失的问题。以下是resize的核心实现,
1 | Node<K,V> loHead = null, loTail = null; |
在实现中会使用两个临时链表,分别存储新地址和旧地址的链表,最后将这两个链表放到对应的位置。
假定出现如下的情况,有ABC三个元素需要移动,首先线程1指向A,next即为B,此后线程2同样进行resize,并把high/low两个链表的更新完成,这时返回线程1继续运行。

但是线程1仍然按照正常的流程继续,A会被放到High链表,B会被放到Low链表,这之后由于B后面没有元素,更新完成,因此C就漏掉了。
其实不管是JDK7还是8,由于链表的很多操作都没有加锁,每个操作也不是原子操作,导致可能出现很多意想不到的结果,也是为什么需要引入专门的ConcurrentHashMap。
ConcurrentHashMap介绍
为什么不使用HashTable?
之前介绍的HashTable也能保证线程安全,但是HashTable使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。正因为如此,需要引入更加高效的多线程解决方案。
ConcurrentHashMap的结构在JDk1.7和1.8中有较大的不同,下面将会分别进行介绍。
JDK1.7中的实现
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment实际继承自可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,每个Segment里包含一个HashEntry数组,我们称之为table,每个HashEntry是一个链表结构的元素。
Segment实际继承自可重入锁(ReentrantLock),这是与普通HashMap的最大区别。
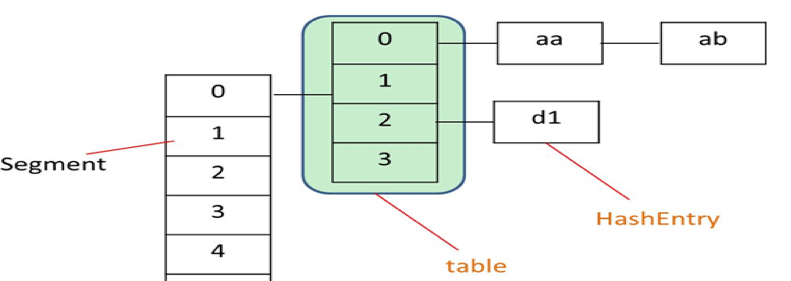
面试点:ConcurrentHashMap实现原理是怎么样的或者ConcurrentHashMap如何在保证高并发下线程安全的同时实现了性能提升?
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它们就可以并发进行。
1.1 初始化过程
初始化有三个参数:
- initialCapacity:初始容量大小 ,默认16。
- loadFactor, 扩容因子或者叫负载因子,默认0.75,当一个Segment存储的元素数量大于initialCapacity* loadFactor时,该Segment会进行一次扩容。
- concurrencyLevel 并发度:默认16。并发度可以理解为程序运行时能够同时操作ConccurentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
以下是对初始化函数的分析:

1.2 Hash值计算
对某个元素进行Put/Get操作之前,都需要定位该元素在哪个segment元素的某个table元素中的,定位的过程,取得key的hashcode值进行一次再散列(通过Wang/Jenkins算法),拿到再散列值后,以再散列值的高位进行取模得到当前元素在哪个segment上。

具体的Hash实现如下:

1.3 Get方法
定位segment和定位table后,依次扫描这个table元素下的的链表,要么找到元素,要么返回null。
在高并发下的情况下如何保证取得的元素是最新的?
用于存储键值对数据的HashEntry,在设计上它的成员变量value等都是volatile类型的,这样就保证别的线程对value值的修改,get方法可以马上看到。
1 | static final class HashEntry<K,V> { |
1.4 Put方法
1、首先定位segment,当这个segment在map初始化后,还为null,由ensureSegment方法负责填充这个segment。
2、对Segment加锁,虽然value是volatile的,只能保证可见性,不能保证原子性。这里put操作不是原子操作,因此需要加锁。

3、定位所在的table元素,并扫描table下的链表,找到时:

注意到默认onlyIfAbsent为false,也就是如果有相同key的元素,会覆盖旧的值。无论是否覆盖,都是返回旧值。
没有找到时:

1.5 扩容操作
扩容操作不会扩容Segment,只会扩容对应的table数组,每次都是将数组翻倍。

之前也提到过,由于数组长度为2次幂,所以每次扩容之后,元素要么在原处,要么在原处加上偏移量为旧的size的新位置。
1.6 Size方法
size的时候进行两次不加锁的统计,两次一致直接返回结果,不一致,重新加锁再次统计,

ConcurrentHashMap的弱一致性
get方法和containsKey方法都是通过对链表遍历判断是否存在key相同的节点以及获得该节点的value。但由于遍历过程中其他线程可能对链表结构做了调整,因此get和containsKey返回的可能是过时的数据,这一点是ConcurrentHashMap在弱一致性上的体现。
JDK1.8中的实现
相比JDK1.7的重要变化:
1、取消了segment数组,引入了Node结构,直接用Node数组来保存数据,锁的粒度更小,减少并发冲突的概率。
2、存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大。什么时候链表转红黑树?当key值相等的元素形成的链表中元素个数超过8个的时候。
2.1 数据结构
- Node:存放实际的key和value值。
- sizeCtl:负数:表示进行初始化或者扩容,-1表示正在初始化,-N,表示有N-1个线程正在进行扩容
正数:0 表示还没有被初始化,>0的数,初始化或者是下一次进行扩容的阈值。 - TreeNode:用在红黑树,表示树的节点, TreeBin是实际放在table数组中的,代表了这个红黑树的根。
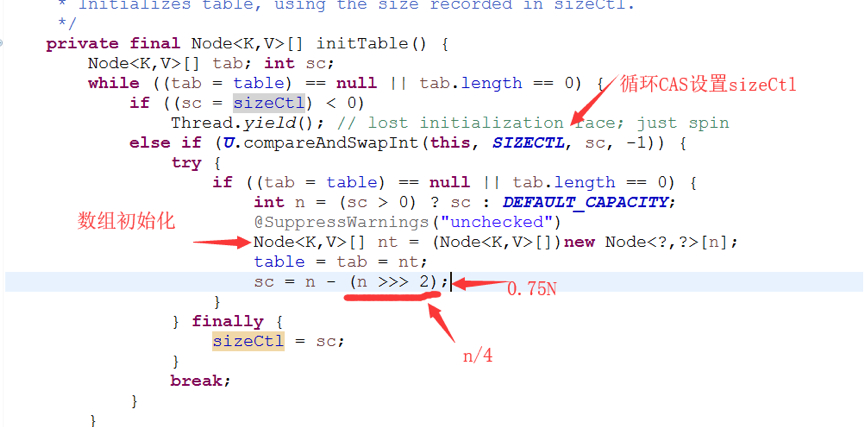
ConcurrentHashMap在初始化时,只是给成员变量赋值,put时进行实际数组的填充。
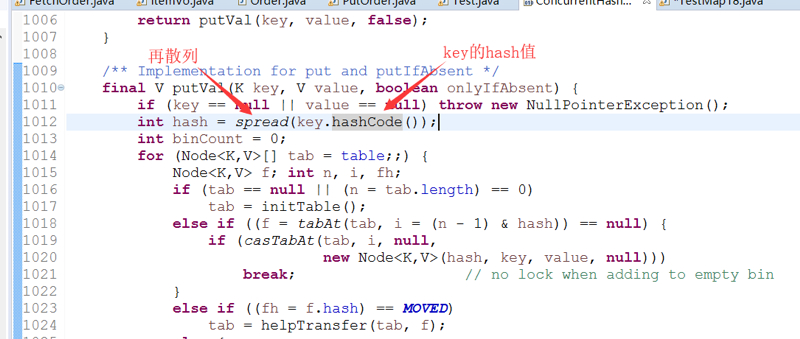
2.2 Hash计算
先计算key的hash值,然后将高位加入计算来进行再散列。

2.3 Get方法
首先计算hash值,确定在table中的位置。
- 是否刚好在table中某个首元素,找到返回;
- 在树中查找
- 在链表中查找

注意到在初始化TreeBin,也就是设置红黑树所在的Node的第一个节点时,会设置对应的hash值,这些hash值定义如下。所以上面的代码中,可以通过判断首节点的hash值<0来确定该节点为树。
1 | static final int MOVED = -1; // hash for forwarding nodes |
2.4 Put方法
PUT方法中会实际初始化数组,


2.5 扩容操作
线程执行put操作,发现容量已经达到扩容阈值,需要进行扩容操作。ConcurrentHashMap支持并发扩容,实现方式是,将表拆分,让每个线程处理自己的区间。如下图:
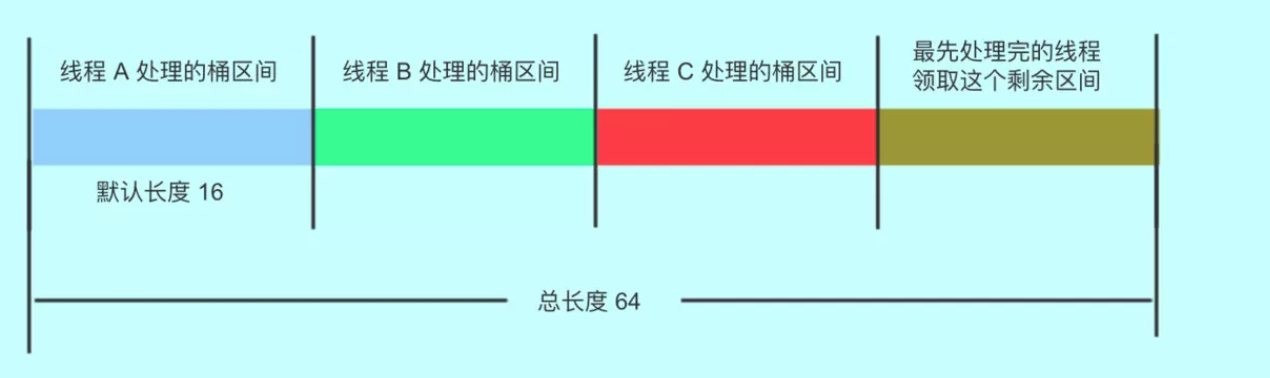
迁移完毕的hash桶,会被设置成ForwardingNode节点,以此告知访问此桶的其他线程,此节点已经迁移完毕。此时线程2访问到了ForwardingNode节点,如果线程2执行的put或remove等写操作,那么就会先帮其扩容。如果线程2执行的是get等读方法,则会调用ForwardingNode的find方法,去nextTable里面查找相关元素。
2.6 Size
Put操作时,addCount 方法用于 CAS 更新 baseCount,但很有可能在高并发的情况下,更新失败,那么这些节点虽然已经被添加到哈希表中了,但是数量却没有被统计。
当更新 baseCount 失败的时候,会调用 fullAddCount 将这些失败的结点包装成一个 CounterCell 对象,保存在 CounterCell 数组中。
整张表实际的 size 其实是 baseCount 加上 CounterCell 数组中元素的个数。
1 | public int size() { |
具体的计算count方法,
1 | final long sumCount() { |
和JDK1.7一样,这样得到的size也只是大概数字,也具有弱一致性。
5.3 ConcurrentSkipListMap
ConcurrentSkipListMap是一个并发安全, 基于skiplist实现有序存储的Map。可以看成是TreeMap的并发版本。
ConcurrentHashMap采用空间换取时间, 但它有着ConcurrentHashMap不能比拟的优点: 有序数据存储.
SkipList的结构如下图所示:
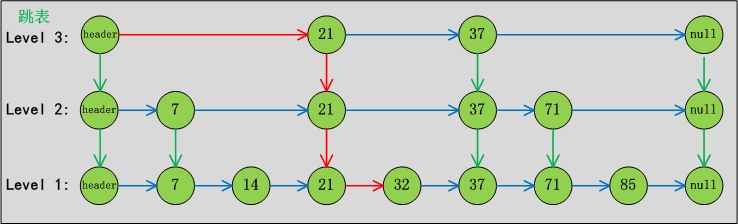
从图中可以得出ConcurrentSkipListMap的几个特点:
- ConcurrentSkipListMap 的节点主要由 Node, Index, HeadIndex 构成;
- ConcurrentSkipListMap 的数据结构横向纵向都是链表
- 最下面那层链表是Node层(数据节点层), 上面几层都是Index层(索引)
- 从纵向链表来看, 最左边的是 HeadIndex 层, 右边的都是Index 层, 且每层的最底端都是对应Node, 纵向上的索引都是指向最底端的Node。
5.4 ConcurrentSkipListSet
ConcurrentSkipListSet基于ConcurrentSkipListMap实现,类似于TreeSet基于TreeMap实现。
5.5 ConcurrentLinkedQueue
ConcurrentLinkedQueue实现了一个高并发的队列,底层使用链表作为其数据结构。从性能角度看,可以算是高并发环境下性能最好的队列了。
ConcurrentLinkedQueue类中,核心节点Node的定义如下,item表示目标元素,next表示当前Node的下一个元素。
1 | private static class Node<E> { |
add,offer将元素插入到尾部,其中add实现上直接调用了offer。peek方法拿头部的数据,但是不移除和poll拿头部的数据,但是同时移除。
5.6 CopyOnWriteArrayList
CopyOnWrite(写时复制)的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再用新的容器替换旧的容器。
好处是我们可以对容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以写时复制容器也是一种读写分离的思想,读和写不同的容器。如果读的时候有多个线程正在向容器添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的,只能保证最终一致性。
下面介绍一下写的过程,
1 | /** |
首先,写入操作使用锁,主要是为了控制写写的情况。接着进行新数组的复制,将新的元素加入newElements,最后使用新的数组替换老的数组,修改就完成了。整个过程不会影响读取,并且修改完成以后,读取线程可以“觉察”到这个修改,因为array是volatile类型,保证了可见性。
1 | /** The array, accessed only via getArray/setArray. */ |
容器的适用场景:适用读多写少的并发场景,常见应用:白名单/黑名单,商品类目的访问和更新场景。但是由于会复制旧的数组,所有可能存在内存占用问题。
5.7 CopyOnWriteArraySet
CopyOnWriteArraySet基于CopyOnWriteArrayList实现,为了保证数据的唯一性,在往其中加入数据时,会check当前数组中是否存在该元素,如果不存在,则加入到当前数组。
1 | /** |
5.8 阻塞队列
定义与常用操作
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:
- 在队列为空时,获取元素的线程会等待队列变为非空。
- 当队列满时,存储元素的线程会等待队列可用。
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列提供了四种处理方法:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove() | poll() | take() | poll(time,unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
- 抛出异常:是指当阻塞队列满时候,再往队列里插入元素,会抛出 IllegalStateException(“Queue full”) 异常。当队列为空时,从队列里获取元素时会抛出 NoSuchElementException 异常 。
- 返回特殊值:插入方法会返回是否成功,成功则返回 true。移除方法,则是从队列里拿出一个元素,如果没有则返回 null
- 一直阻塞:当阻塞队列满时,如果生产者线程往队列里 put 元素,队列会一直阻塞生产者线程,直到拿到数据,或者响应中断退出。当队列空时,消费者线程试图从队列里 take 元素,队列也会阻塞消费者线程,直到队列可用。
- 超时退出:当阻塞队列满时,队列会阻塞生产者线程一段时间,如果超过一定的时间,生产者线程就会退出。
Java里的阻塞队列
JDK7 提供了 7 个阻塞队列。分别是
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
1. ArrayBlockingQueue
ArrayBlockingQueue 是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列,所谓公平访问队列是指阻塞的所有生产者线程或消费者线程,当队列可用时,可以按照阻塞的先后顺序访问队列,即先阻塞的生产者线程,可以先往队列里插入元素,先阻塞的消费者线程,可以先从队列里获取元素。通常情况下为了保证公平性会降低吞吐量。我们可以使用以下代码创建一个公平的阻塞队列:
2. LinkedBlockingQueue
一个用链表实现的有界阻塞队列。此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
3. PriorityBlockingQueue
一个支持优先级的无界队列。默认情况下元素采取自然顺序排列,也可以通过比较器 comparator 来指定元素的排序规则。元素按照升序排列。
4. DelayQueue
一个支持延时获取元素的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将 DelayQueue 运用在以下应用场景:
缓存系统的设计:可以用 DelayQueue 保存缓存元素的有效期,使用一个线程循环查询 DelayQueue,一旦能从 DelayQueue 中获取元素时,表示缓存有效期到了。
定时任务调度。使用 DelayQueue 保存当天将会执行的任务和执行时间,一旦从 DelayQueue 中获取到任务就开始执行,从比如 TimerQueue 就是使用 DelayQueue 实现的。
队列中的 Delayed 必须实现 compareTo 来指定元素的顺序。比如让延时时间最长的放在队列的末尾。
5. SynchronousQueue
SynchronousQueue 是一个不存储元素的阻塞队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。SynchronousQueue 可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合于传递性场景, 比如在一个线程中使用的数据,传递给另外一个线程使用,SynchronousQueue 的吞吐量高于 LinkedBlockingQueue 和 ArrayBlockingQueue。
6. LinkedTransferQueue
是一个由链表结构组成的无界阻塞 TransferQueue 队列。相对于其他阻塞队列,LinkedTransferQueue 多了 tryTransfer 和 transfer 方法。
- transfer 方法。如果当前有消费者正在等待接收元素(消费者使用 take() 方法或带时间限制的 poll() 方法时),transfer 方法可以把生产者传入的元素立刻 transfer(传输)给消费者。如果没有消费者在等待接收元素,transfer 方法会将元素存放在队列的 tail 节点,并等到该元素被消费者消费了才返回。transfer 方法的关键代码如下:
1 | Node pred = tryAppend(s, haveData); |
第一行代码是试图把存放当前元素的 s 节点作为 tail 节点。第二行代码是让 CPU 自旋等待消费者消费元素。因为自旋会消耗 CPU,所以自旋一定的次数后使用 Thread.yield() 方法来暂停当前正在执行的线程,并执行其他线程。
- tryTransfer 方法。则是用来试探下生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回 false。和 transfer 方法的区别是 tryTransfer 方法无论消费者是否接收,方法立即返回。而 transfer 方法是必须等到消费者消费了才返回。
对于带有时间限制的 tryTransfer(E e, long timeout, TimeUnit unit) 方法,则是试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待指定的时间再返回,如果超时还没消费元素,则返回 false,如果在超时时间内消费了元素,则返回 true。
7. LinkedBlockingDeque
一个由链表结构组成的双向阻塞队列。所谓双向队列指的你可以从队列的两端插入和移出元素。双端队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他的阻塞队列,LinkedBlockingDeque 多了 addFirst,addLast,offerFirst,offerLast,peekFirst,peekLast 等方法,以 First 单词结尾的方法,表示插入,获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入,获取或移除双端队列的最后一个元素。另外插入方法 add 等同于 addLast,移除方法 remove 等效于 removeFirst。但是 take 方法却等同于 takeFirst,不知道是不是 Jdk 的 bug,使用时还是用带有 First 和 Last 后缀的方法更清楚。
在初始化 LinkedBlockingDeque 时可以设置容量防止其过渡膨胀。另外双向阻塞队列可以运用在“工作窃取”模式中。
阻塞队列的实现原理
在介绍阻塞队列的实现之前,先介绍一下生产者与消费者模式:
生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这种生产消费能力不均衡的问题,便有了生产者和消费者模式。
生产者和消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
1)当队列满的时候,插入元素的线程被阻塞,直达队列不满。
2)队列为空的时候,获取元素的线程被阻塞,直到队列不空。
JDK是如何让生产者和消费者能够高效率的进行通讯呢?
答案是使用通知模式实现。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
以ArrayBlockingQueue为例:
1 | private final Condition notFull; |
从上述代码可以看到,当队列为空,notEmpty进行等待;插入元素后,唤醒等待的线程。当队列满时,notFull进行等待;删除元素后,唤醒等待的线程。
参考:
本文由『后端精进之路』原创,首发于博客 http://teckee.github.io/ , 转载请注明出处
搜索『后端精进之路』关注公众号,立刻获取最新文章和价值2000元的BATJ精品面试课程。
