6. 线程池 6.1 基本概念 在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理。如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题:如果并发的请求数量非常多,但每个线程执行的时间很短,这样就会频繁的创建和销毁线程,如此一来会大大降低系统的效率。可能出现服务器在为每个请求创建新线程和销毁线程上花费的时间和消耗的系统资源要比处理实际的用户请求的时间和资源更多。
那么有没有一种办法使执行完一个任务,并不被销毁,而是可以继续执行其他的任务呢?这就是线程池的目的了。线程池为线程生命周期的开销和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上。
什么时候使用线程池?
使用线程池好处
降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
6.2 实现自己的线程池 实现的线程池需要满足以下基本条件:
1、线程必须在池子已经创建好了,并且可以保持住,要有容器保存多个线程;
以下是线程池的具体实现:
线程池中实现了任务队列,用来保存所有的任务;工作线程,来执行具体的任务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public class MyThreadPool2 { // 线程池中默认线程的个数为5 private static int WORK_NUM = 5; // 队列默认任务个数为100 private static int TASK_COUNT = 100; // 用户在构造这个池,希望的启动的线程数 private final int worker_num; // 工作线程组 private WorkThread[] workThreads; // 任务队列,作为一个缓冲 private final BlockingQueue<Runnable> taskQueue; // 创建具有默认线程个数的线程池 public MyThreadPool2() { this(WORK_NUM,TASK_COUNT); } // 创建线程池,worker_num为线程池中工作线程的个数 public MyThreadPool2(int worker_num,int taskCount) { if (worker_num<=0) worker_num = WORK_NUM; if(taskCount<=0) taskCount = TASK_COUNT; this.worker_num = worker_num; taskQueue = new ArrayBlockingQueue<>(taskCount); workThreads = new WorkThread[worker_num]; for(int i=0;i<worker_num;i++) { workThreads[i] = new WorkThread(); workThreads[i].start(); } } // 执行任务,其实只是把任务加入任务队列,什么时候执行有线程池管理器决定 public void execute(Runnable task) { try { taskQueue.put(task); } catch (InterruptedException e) { e.printStackTrace(); } } // 销毁线程池,该方法保证在所有任务都完成的情况下才销毁所有线程,否则等待任务完成才销毁 public void destroy() { // 工作线程停止工作,且置为null System.out.println("ready close pool....."); for(int i=0;i<worker_num;i++) { workThreads[i].stopWorker(); workThreads[i] = null;//help gc } taskQueue.clear();// 清空任务队列 } // 覆盖toString方法,返回线程池信息:工作线程个数和已完成任务个数 @Override public String toString() { return "WorkThread number:" + worker_num + " wait task number:" + taskQueue.size(); } /** * 内部类,工作线程 */ private class WorkThread extends Thread{ @Override public void run(){ Runnable r = null; try { while (!isInterrupted()) { r = taskQueue.take(); if(r!=null) { System.out.println(getId()+" ready exec :"+r); r.run(); } r = null;//help gc; } } catch (Exception e) { // TODO: handle exception } } public void stopWorker() { interrupt(); } } }
以下是测试程序:
分别创建多个任务,并放入线程池进行执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class TestMyThreadPool { public static void main(String[] args) throws InterruptedException { // 创建3个线程的线程池 MyThreadPool2 t = new MyThreadPool2(3,0); t.execute(new MyTask("testA")); t.execute(new MyTask("testB")); t.execute(new MyTask("testC")); t.execute(new MyTask("testD")); t.execute(new MyTask("testE")); t.execute(new MyTask("testF")); t.execute(new MyTask("testG")); t.execute(new MyTask("testH")); System.out.println(t); Thread.sleep(10000); t.destroy();// 所有线程都执行完成才destory System.out.println(t); } // 任务类 static class MyTask implements Runnable { private String name; private Random r = new Random(); public MyTask(String name) { this.name = name; } public String getName() { return name; } @Override public void run() {// 执行任务 try { Thread.sleep(r.nextInt(1000)+2000); } catch (InterruptedException e) { System.out.println(Thread.currentThread().getId()+" sleep InterruptedException:" +Thread.currentThread().isInterrupted()); } System.out.println("任务 " + name + " 完成"); } } }
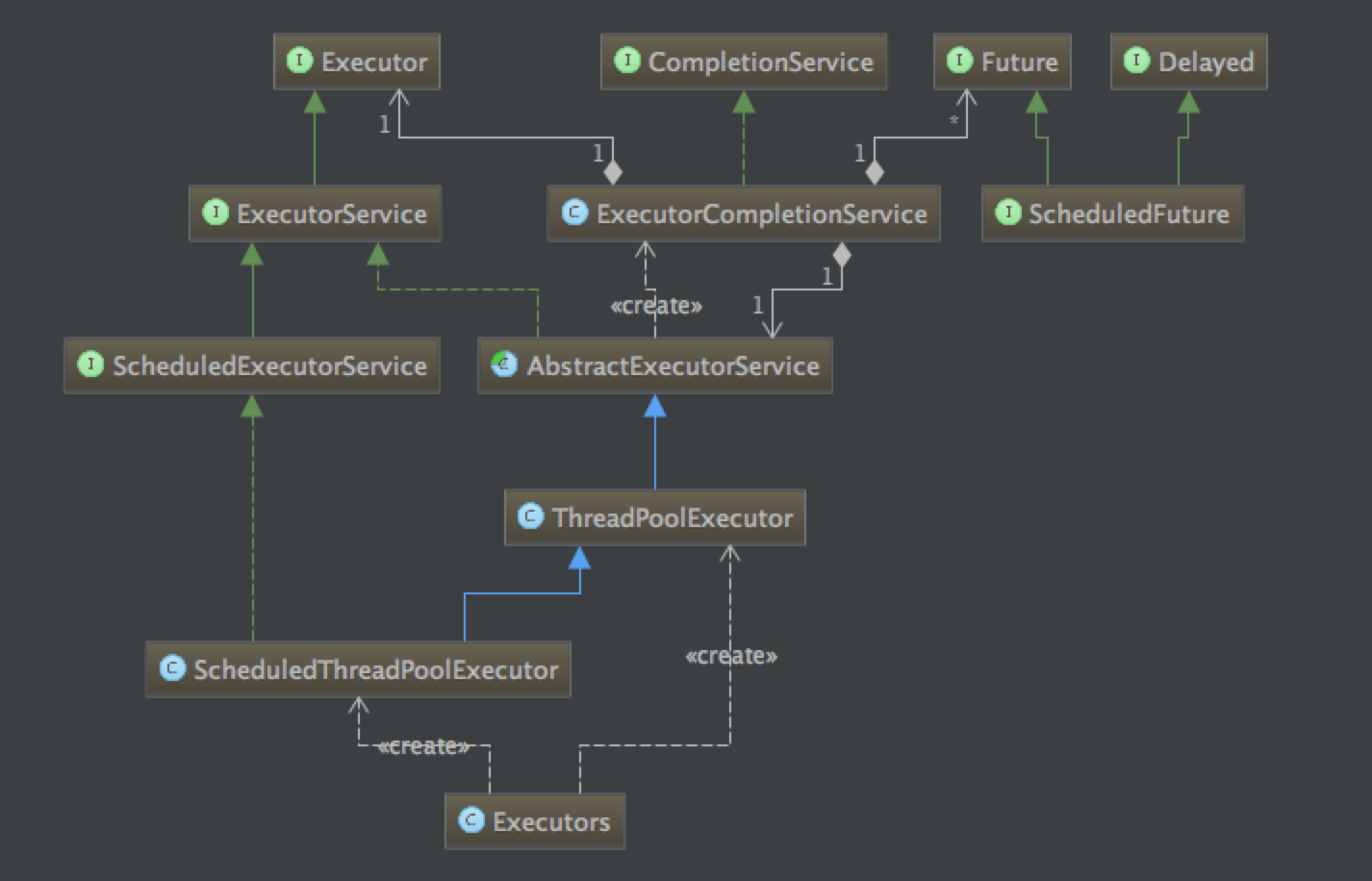
6.3 Executor框架 Executor框架是一个根据一组执行策略调用,调度,执行和控制的异步任务的框架,目的是提供一种将”任务提交”与”任务如何运行”分离开来的机制。
Executor框架的类继承关系如下图:
J.U.C中有三个Executor接口:
Executor:一个运行新任务的简单接口;
ExecutorService:扩展了Executor接口。添加了一些用来管理执行器生命周期和任务生命周期的方法;
ScheduledExecutorService:扩展了ExecutorService。支持Future和定期执行任务。
下面分别进行介绍:
1. Executor接口 Executor接口只有一个execute方法,用来替代通常创建或启动线程的方法。
1 2 3 public interface Executor { void execute(Runnable command); }
Executor接口只有一个execute方法,用来替代通常创建或启动线程的方法。
1 executor.execute(new Thread())
对于不同的Executor实现,execute()方法可能是创建一个新线程并立即启动,也有可能是使用已有的工作线程来运行传入的任务,也可能是根据设置线程池的容量或者阻塞队列的容量来决定是否要将传入的线程放入阻塞队列中或者拒绝接收传入的线程。
2. ExecutorService接口 ExecutorService接口继承自Executor接口,提供了管理终止的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。增加了shutDown(),shutDownNow(),invokeAll(),invokeAny()和submit()等方法。如果需要支持即时关闭,也就是shutDownNow()方法,则任务需要正确处理中断。
3. ScheduledExecutorService接口 ScheduledExecutorService扩展ExecutorService接口并增加了schedule方法。调用schedule方法可以在指定的延时后执行一个Runnable或者Callable任务。ScheduledExecutorService接口还定义了按照指定时间间隔定期执行任务的scheduleAtFixedRate()方法和scheduleWithFixedDelay()方法。
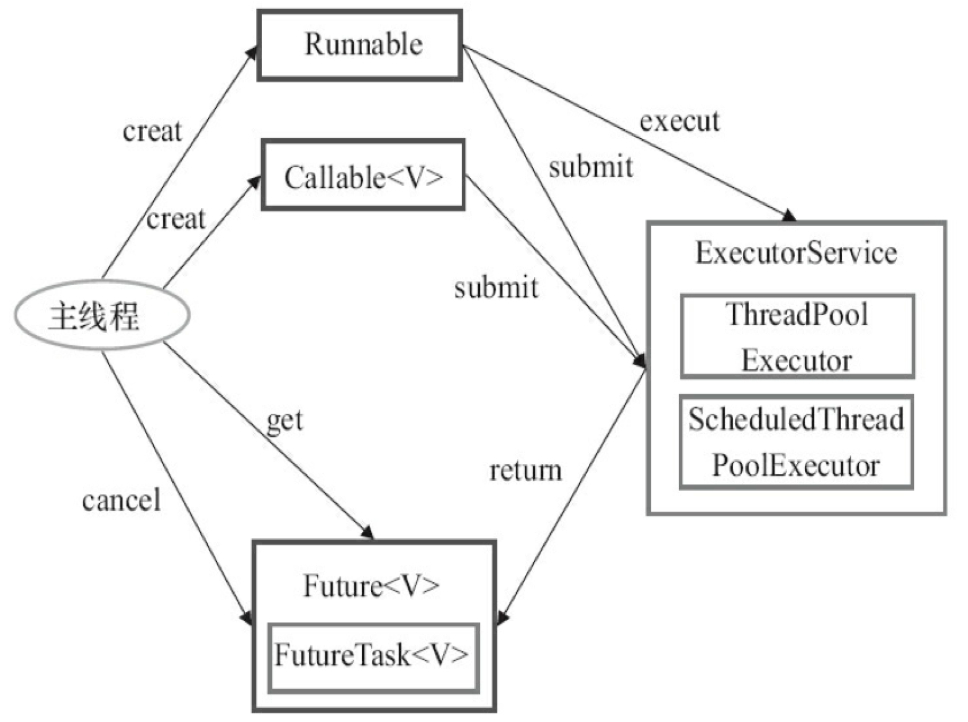
4. Executor框架基本使用流程 基本使用流程如下:
6.4 ThreadPoolExecutor分析 ThreadPoolExecutor继承自AbstractExecutorService,也实现了ExecutorService接口。JDK中的提供的内置线程池基本都基于ThreadPoolExecutor实现,后面会仔细介绍。
构造函数及参数意义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
构造方法中的字段含义如下:
corePoolSize :线程池中核心线程数,运行的线程数<corePoolSize,就会创建新线程,>= corePoolSize,这个任务就会保存到BlockingQueue,如果调用prestartAllCoreThreads()方法就会一次性的启动corePoolSize个数的线程。
maximumPoolSize : 允许的最大线程数,BlockingQueue也满了,< maximumPoolSize时候就会再次创建新的线程.
keepAliveTime : 线程空闲下来后,存活的时间,这个参数只在 >corePoolSize 才有用.
TimeUnit unit: 存活时间的单位值.
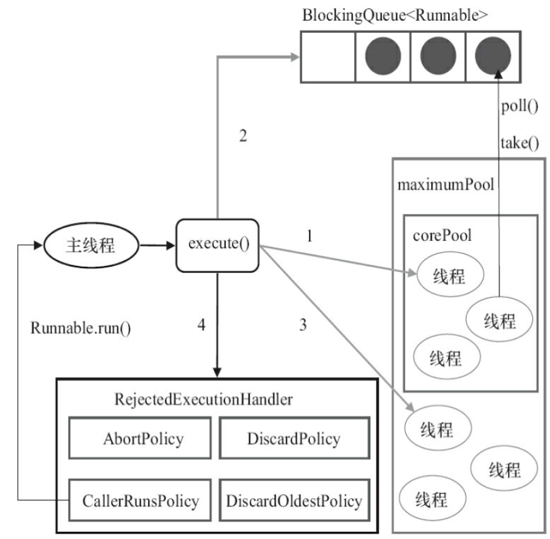
workQueue :保存等待执行的任务的阻塞队列,当提交一个新的任务到线程池以后, 线程池会根据当前线程池中正在运行着的线程的数量来决定对该任务的处理方式,主要有以下几种处理方式:
使用直接切换队列:这种方式常用的队列是SynchronousQueue.
使用无界队列:一般使用基于链表的阻塞队列LinkedBlockingQueue。如果使用这种方式,那么线程池中能够创建的最大线程数就是corePoolSize,而maximumPoolSize就不会起作用了(后面也会说到)。当线程池中所有的核心线程都是RUNNING状态时,这时一个新的任务提交就会放入等待队列中。
使用有界队列:一般使用ArrayBlockingQueue。使用该方式可以将线程池的最大线程数量限制为maximumPoolSize,这样能够降低资源的消耗,但同时这种方式也使得线程池对线程的调度变得更困难,因为线程池和队列的容量都是有限的值,所以要想使线程池处理任务的吞吐率达到一个相对合理的范围,又想使线程调度相对简单,并且还要尽可能的降低线程池对资源的消耗,就需要合理的设置这两个数量。
threadFactory :它是ThreadFactory类型的变量,用来创建新线程。默认使用Executors.defaultThreadFactory() 来创建线程。使用默认的ThreadFactory来创建线程时,会使新创建的线程具有相同的NORM_PRIORITY优先级并且是非守护线程,同时也设置了线程的名称。
handler :它是RejectedExecutionHandler类型的变量,表示线程池的饱和策略。如果阻塞队列满了并且没有空闲的线程,这时如果继续提交任务,就需要采取一种策略处理该任务。
线程池提供了4种策略:
AbortPolicy:直接抛出异常,这是默认策略;
CallerRunsPolicy:用调用者所在的线程来执行任务;
DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
DiscardPolicy:直接丢弃任务;
任务执行 提交任务执行,主要有execute和submit两种方式,主要区别是后者需要有返回值。
execute(Runnable command)
Future submit(Callable task)
下面主要介绍execute的流程:
简单来说,在执行execute()方法时且状态一直是RUNNING时,的执行过程如下:
如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务;
如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中;
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务;
如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
整个流程可以用下图来总结:
接下来结合代码进行分析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /* * clt记录着runState和workerCount */ int c = ctl.get(); /* * workerCountOf方法取出低29位的值,表示当前活动的线程数; * 如果当前活动线程数小于corePoolSize,则新建一个线程放入线程池中; * 并把任务添加到该线程中。 */ if (workerCountOf(c) < corePoolSize) { /* * addWorker中的第二个参数表示限制添加线程的数量是根据corePoolSize来判断还是maximumPoolSize来判断; * 如果为true,根据corePoolSize来判断; * 如果为false,则根据maximumPoolSize来判断 */ if (addWorker(command, true)) return; /* * 如果添加失败,则重新获取ctl值 */ c = ctl.get(); } /* * 如果当前线程池是运行状态并且任务添加到队列成功 */ if (isRunning(c) && workQueue.offer(command)) { // 重新获取ctl值 int recheck = ctl.get(); // 再次判断线程池的运行状态,如果不是运行状态,由于之前已经把command添加到workQueue中了, // 这时需要移除该command // 执行过后通过handler使用拒绝策略对该任务进行处理,整个方法返回 if (! isRunning(recheck) && remove(command)) reject(command); /* * 获取线程池中的有效线程数,如果数量是0,则执行addWorker方法 * 这里传入的参数表示: * 1. 第一个参数为null,表示在线程池中创建一个线程,但不去启动; * 2. 第二个参数为false,将线程池的有限线程数量的上限设置为maximumPoolSize,添加线程时根据maximumPoolSize来判断; * 如果判断workerCount大于0,则直接返回,在workQueue中新增的command会在将来的某个时刻被执行。 */ else if (workerCountOf(recheck) == 0) addWorker(null, false); } /* * 如果执行到这里,有两种情况: * 1. 线程池已经不是RUNNING状态; * 2. 线程池是RUNNING状态,但workerCount >= corePoolSize并且workQueue已满。 * 这时,再次调用addWorker方法,但第二个参数传入为false,将线程池的有限线程数量的上限设置为maximumPoolSize; * 如果失败则拒绝该任务 */ else if (!addWorker(command, false)) reject(command); }
addWorker方法的主要工作是在线程池中创建一个新的线程并执行,firstTask参数 用于指定新增的线程执行的第一个任务,core参数为true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 private boolean addWorker(Runnable firstTask, boolean core) { retry: for (;;) { int c = ctl.get(); // 获取运行状态 int rs = runStateOf(c); /* * 这个if判断 * 如果rs >= SHUTDOWN,则表示此时不再接收新任务; * 接着判断以下3个条件,只要有1个不满足,则返回false: * 1. rs == SHUTDOWN,这时表示关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务 * 2. firsTask为空 * 3. 阻塞队列不为空 * * 首先考虑rs == SHUTDOWN的情况 * 这种情况下不会接受新提交的任务,所以在firstTask不为空的时候会返回false; * 然后,如果firstTask为空,并且workQueue也为空,则返回false, * 因为队列中已经没有任务了,不需要再添加线程了 */ // Check if queue empty only if necessary. if (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty())) return false; for (;;) { // 获取线程数 int wc = workerCountOf(c); // 如果wc超过CAPACITY,也就是ctl的低29位的最大值(二进制是29个1),返回false; // 这里的core是addWorker方法的第二个参数,如果为true表示根据corePoolSize来比较, // 如果为false则根据maximumPoolSize来比较。 // if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false; // 尝试增加workerCount,如果成功,则跳出第一个for循环 if (compareAndIncrementWorkerCount(c)) break retry; // 如果增加workerCount失败,则重新获取ctl的值 c = ctl.get(); // Re-read ctl // 如果当前的运行状态不等于rs,说明状态已被改变,返回第一个for循环继续执行 if (runStateOf(c) != rs) continue retry; // else CAS failed due to workerCount change; retry inner loop } } boolean workerStarted = false; boolean workerAdded = false; Worker w = null; try { // 根据firstTask来创建Worker对象 w = new Worker(firstTask); // 每一个Worker对象都会创建一个线程 final Thread t = w.thread; if (t != null) { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int rs = runStateOf(ctl.get()); // rs < SHUTDOWN表示是RUNNING状态; // 如果rs是RUNNING状态或者rs是SHUTDOWN状态并且firstTask为null,向线程池中添加线程。 // 因为在SHUTDOWN时不会在添加新的任务,但还是会执行workQueue中的任务 if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); // workers是一个HashSet workers.add(w); int s = workers.size(); // largestPoolSize记录着线程池中出现过的最大线程数量 if (s > largestPoolSize) largestPoolSize = s; workerAdded = true; } } finally { mainLock.unlock(); } if (workerAdded) { // 启动线程 t.start(); workerStarted = true; } } } finally { if (! workerStarted) addWorkerFailed(w); } return workerStarted; }
关闭线程池 关闭线程池通常有如下两种方式:
shutdownNow():设置线程池的状态,还会尝试停止正在运行或者暂停任务的线程
shutdown():设置线程池的状态,只会中断所有没有执行任务的线程
线程池的参数配置 通常来讲,根据任务的性质来分,可以划分为:计算密集型(CPU),IO密集型,混合型。
计算密集型:加密,大数分解,正则等,线程数适当小一点,最大推荐:机器的Cpu核心数+1,为什么+1,防止页缺失,(机器的Cpu核心=Runtime.getRuntime().availableProcessors();)
IO密集型:读取文件,数据库连接,网络通讯, 线程数适当大一点,可以设置为机器的Cpu核心数*2。
混合型:尽量拆分,IO密集型>>计算密集型,拆分意义不大,IO密集型~=计算密集型
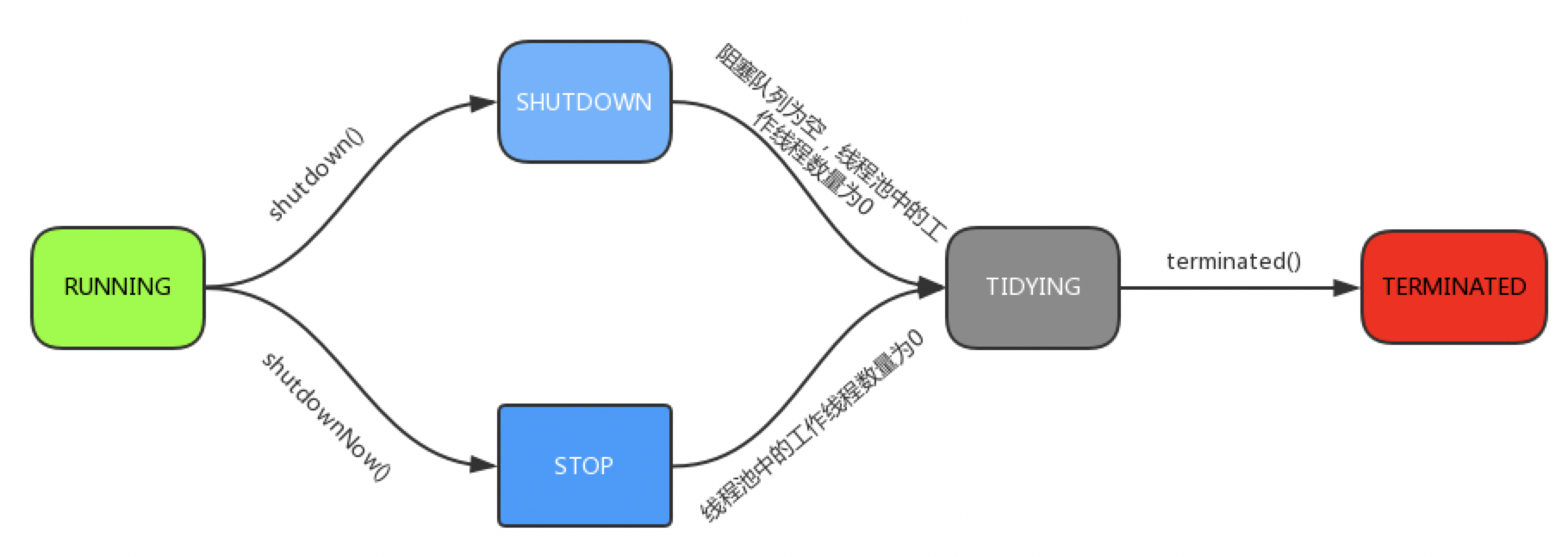
线程池的状态 线程池的运行状态. 线程池一共有五种状态, 分别是:
RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务;
SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。(finalize() 方法在执行过程中也会调用shutdown()方法进入该状态);
STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态;
TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
TERMINATED:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。
线程池不是RUNNING状态;
线程池状态不是TIDYING状态或TERMINATED状态;
如果线程池状态是SHUTDOWN并且workerQueue为空;
workerCount为0;
设置TIDYING状态成功。
下图是线程池的状态转换过程,
6.5 Executors内置线程池 通常开发者都是利用 Executors 提供的通用线程池创建方法,去创建不同配置的线程池,主要区别在于不同的 ExecutorService 类型或者不同的初始参数。
newCachedThreadPool(),它是一种用来处理大量短时间工作任务的线程池,具有几个鲜明特点:它会试图缓存线程并重用,当无缓存线程可用时,就会创建新的工作线程;如果线程闲置的时间超过60秒,则被终止并移出缓存;长时间闲置时,这种线程池,不会消耗什么资源。其内部使用 SynchronousQueue 作为工作队列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 /** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available. These pools will typically improve the performance * of programs that execute many short-lived asynchronous tasks. * Calls to {@code execute} will reuse previously constructed * threads if available. If no existing thread is available, a new * thread will be created and added to the pool. Threads that have * not been used for sixty seconds are terminated and removed from * the cache. Thus, a pool that remains idle for long enough will * not consume any resources. Note that pools with similar * properties but different details (for example, timeout parameters) * may be created using {@link ThreadPoolExecutor} constructors. * * @return the newly created thread pool */ public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
newFixedThreadPool(int nThreads),创建固定数目(nThreads)的线程,其背后使用的是无界的工作队列,任何时候最多有 nThreads 个工作线程是活动的。这意味着,如果任务数量超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线程退出,将会有新的工作线程被创建,以补足指定的数目nThreads。
1 2 3 4 5 public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
newSingleThreadExecutor(),它的特点在于工作线程数目被限制为1,操作一个无界的工作队列,所以它保证了所有任务的都是被顺序执行,最多会有一个任务处于活动状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目。
1 2 3 4 5 6 7 public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory)); }
newWorkStealingPool(int parallelism),这是一个经常被人忽略的线程池,Java 8 才加入这个创建方法,其内部会构建ForkJoinPool,利用Work-Stealing算法,并行地处理任务,不保证处理顺序。
1 2 3 4 5 public ForkJoinPool() { this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()), defaultForkJoinWorkerThreadFactory, null, false, 0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS); }
newSingleThreadScheduledExecutor() 和 newScheduledThreadPool(int corePoolSize),创建的是个 ScheduledExecutorService,可以进行定时或周期性的工作调度,区别在于单一工作线程还是多个工作线程。
1 2 3 4 public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService (new ScheduledThreadPoolExecutor(1)); }
1 2 3 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
以下是ScheduledThreadPoolExecutor的构造函数,该类继承于ThreadPoolExecutor,可以看到任务存放在DelayedWorkQueue。
1 2 3 4 5 public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, new DelayedWorkQueue()); }
类中提供了多种执行定时任务的方法,
1 2 3 4 public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit); public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit); public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit); public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
总结下来,主要分三种:
schedule:只执行一次,任务还可以延时执行
scheduleAtFixedRate:提交固定时间间隔的任务
scheduleWithFixedDelay:提交固定延时间隔执行的任务
注意scheduleAtFixedRate和scheduleWithFixedDelay的区别,下图给出了两者执行任务时间上的示意图。scheduleAtFixedRate总是间隔固定的时间来执行task,但是如果下图中Task1执行超时,也就是超过了Fixed Time,当Task1执行完之后,Task2将立刻执行。scheduleWithFixedDelay不同的是,每个任务总是在上一个任务结束之后,等待固定的Fixed Delay Time后开始执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class ScheduleWorkerTime implements Runnable{ public final static int Long_8 = 8;//任务耗时8秒 public final static int Short_2 = 2;//任务耗时2秒 public final static int Normal_5 = 5;//任务耗时5秒 public static SimpleDateFormat formater = new SimpleDateFormat( "HH:mm:ss"); public static AtomicInteger count = new AtomicInteger(0); @Override public void run() { if(count.get()==0) { System.out.println("Long_8....begin:"+formater.format(new Date())); SleepTools.second(Long_8); System.out.println("Long_8....end:"+formater.format(new Date())); count.incrementAndGet(); }else if(count.get()==1) { System.out.println("Short_2 ...begin:"+formater.format(new Date())); SleepTools.second(Short_2); System.out.println("Short_2 ...end:"+formater.format(new Date())); count.incrementAndGet(); }else { System.out.println("Normal_5...begin:"+formater.format(new Date())); SleepTools.second(Normal_5); System.out.println("Normal_5...end:"+formater.format(new Date())); count.incrementAndGet(); } } public static void main(String[] args) { ScheduledThreadPoolExecutor schedule = new ScheduledThreadPoolExecutor(1); //任务间隔6秒 schedule.scheduleAtFixedRate(new ScheduleWorkerTime(), 0, 6000, TimeUnit.MILLISECONDS); } }
代码中定义了3个任务,分别执行8s,2s,5s,设置的固定间隔为6s。从输出结果可以看到,第一个场任务结束后,第二个任务立刻开始执行,第二个任务执行完时,到了10s,此时等待2s后,第三个任务开始执行。由此可以看到,当前序任务没超时,后续任务会按照指定的时间进行执行;如果有超时,则会马上执行。
1 2 3 4 5 6 7 执行结果如下: Long_8....begin:14:56:27 Long_8....end:14:56:35 Short_2 ...begin:14:56:35 Short_2 ...end:14:56:37 Normal_5...begin:14:56:39 Normal_5...end:14:56:44
注意最好在提交给ScheduledThreadPoolExecutor的任务要catch异常,否则发生异常之后,程序会终止运行。
6.6 CompletionService 使用场景 当向Executor提交多个任务并且希望获得它们在完成之后的结果,如果用FutureTask,可以循环获取task,并调用get方法去获取task执行结果,但是如果task还未完成,获取结果的线程将阻塞直到task完成,由于不知道哪个task优先执行完毕,使用这种方式效率不会很高。
在jdk5时候提出接口CompletionService,它整合了Executor和BlockingQueue的功能,可以更加方便在多个任务执行时,按任务完成顺序获取结果。
使用流程 CompletionService的使用流程如下:
声明task执行载体,线程池executor;
声明CompletionService,来包装执行task的线程池,存放已完成状态task的阻塞队列,队列默认为基于链表结构的阻塞队列LinkedBlockingQueue;
调用submit方法提交task;
调用take方法获取已完成状态task。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 public class CompletionServiceTest { // 声明线程池 private static ExecutorService executorService = Executors.newFixedThreadPool(100); public void test() { // 声明CompletionService包装Executor CompletionService<Long> completionService = new ExecutorCompletionService<Long>(executorService); final int groupNum = 10000000 / 100; for ( int i = 1; i <= 100; i++) { int start = (i-1) * groupNum + 1; int end = i * groupNum; completionService.submit(new Callable<Long>() { @Override public Long call() throws Exception { Long sum = 0L; for (int j = start; j <= end; j++) { sum += j; } return sum; } }); } long result = 0L; try { for (int i = 0; i < 100; i++) { long taskResult = completionService.take().get(); System.out.println(taskResult); result += taskResult; } } catch (Exception e) { e.printStackTrace(); } System.out.println("the result is " + result); } public static void main(String[] args) { new CompletionServiceTest().test(); } }
源码分析 CompletionService接口提供五个方法:
Future submit(Callable task)
Future submit(Runnable task, V result)
Future take() throws InterruptedException
Future poll()
Future poll(long timeout, TimeUnit unit) throws InterruptedException
CompletionService与普通用FutureTask获取结果的最大不同是,可以按照任务完成的顺序返回结果。具体是如何实现的呢?
内部封装了一个QueueingFuture对象,并且实现了done方法,在task执行完成之后将当前task添加到completionQueue。
1 2 3 4 5 6 7 8 9 10 11 private static class QueueingFuture<V> extends FutureTask<Void> { QueueingFuture(RunnableFuture<V> task, BlockingQueue<Future<V>> completionQueue) { super(task, null); this.task = task; this.completionQueue = completionQueue; } private final Future<V> task; private final BlockingQueue<Future<V>> completionQueue; protected void done() { completionQueue.add(task); } }
done方法将在FutureTask的finishCompletion方法中被调用。只是默认done方法是空的,completionQueue实现了该方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 /** * Removes and signals all waiting threads, invokes done(), and * nulls out callable. */ private void finishCompletion() { // assert state > COMPLETING; for (WaitNode q; (q = waiters) != null;) { if (WAITERS.weakCompareAndSet(this, q, null)) { for (;;) { Thread t = q.thread; if (t != null) { q.thread = null; LockSupport.unpark(t); } WaitNode next = q.next; if (next == null) break; q.next = null; // unlink to help gc q = next; } break; } } done(); callable = null; // to reduce footprint }
参考:
本文由『后端精进之路』原创,首发于博客 http://teckee.github.io/ , 转载请注明出处
搜索『后端精进之路』关注公众号,立刻获取最新文章和价值2000元的BATJ精品面试课程 。